基于情绪识别的游戏难度调节方法、系统、设备及介质与流程-j9九游会真人
1.本发明属于游戏难度调节技术领域,具体涉及一种基于情绪识别的游戏难度调节方法、系统、设备及介质。
背景技术:
2.随着感知和情感计算技术的发展,实现游戏根据用户情绪状态调整难度的想法也被逐步提出。
3.早期的相关研究主要基于检测单一生理信号变化来推断用户情绪,仅能做出简单的游戏参数调整,实现的自适应效果有限。如现有技术中公开的公开号为cn109758767a,名称为游戏难度调整方法、终端及计算机可读存储的发明专利申请中,主要公开了获取用户的脑电波信号,对所述脑电波信号进行处理,得到对应的专注度指数、放松度指数和疲劳度指数;根据所述专注度指数、放松度指数、疲劳度指数和预设映射关系表得到对应的专注度分值、放松度分值和疲劳度分值;根据所述专注度分值、放松度分值和疲劳度分值计算得到游戏状态分值,并根据所述游戏状态分值对应调整游戏难度,其利用单一的脑电波信号得到用户的情绪状态,做出游戏难度调整。
4.进入当前的信息时代后,各类先进传感器的出现使得能同时采集用户的多源生理数据,如脑电图、面部表情等,还可利用深度学习等技术处理这些多源生理数据,因此,如何运用多源生理数据,实现智能化的个性化的游戏难度调节仍有进一步的改进空间。
技术实现要素:
5.本发明的目的在于提供一种基于情绪识别的游戏难度调节方法、系统、设备及介质,能够通过多源生理数据准确获取用户的当前情绪,根据用户的当前情绪和理想情绪计算难度调整值实现个性化的难度调节。
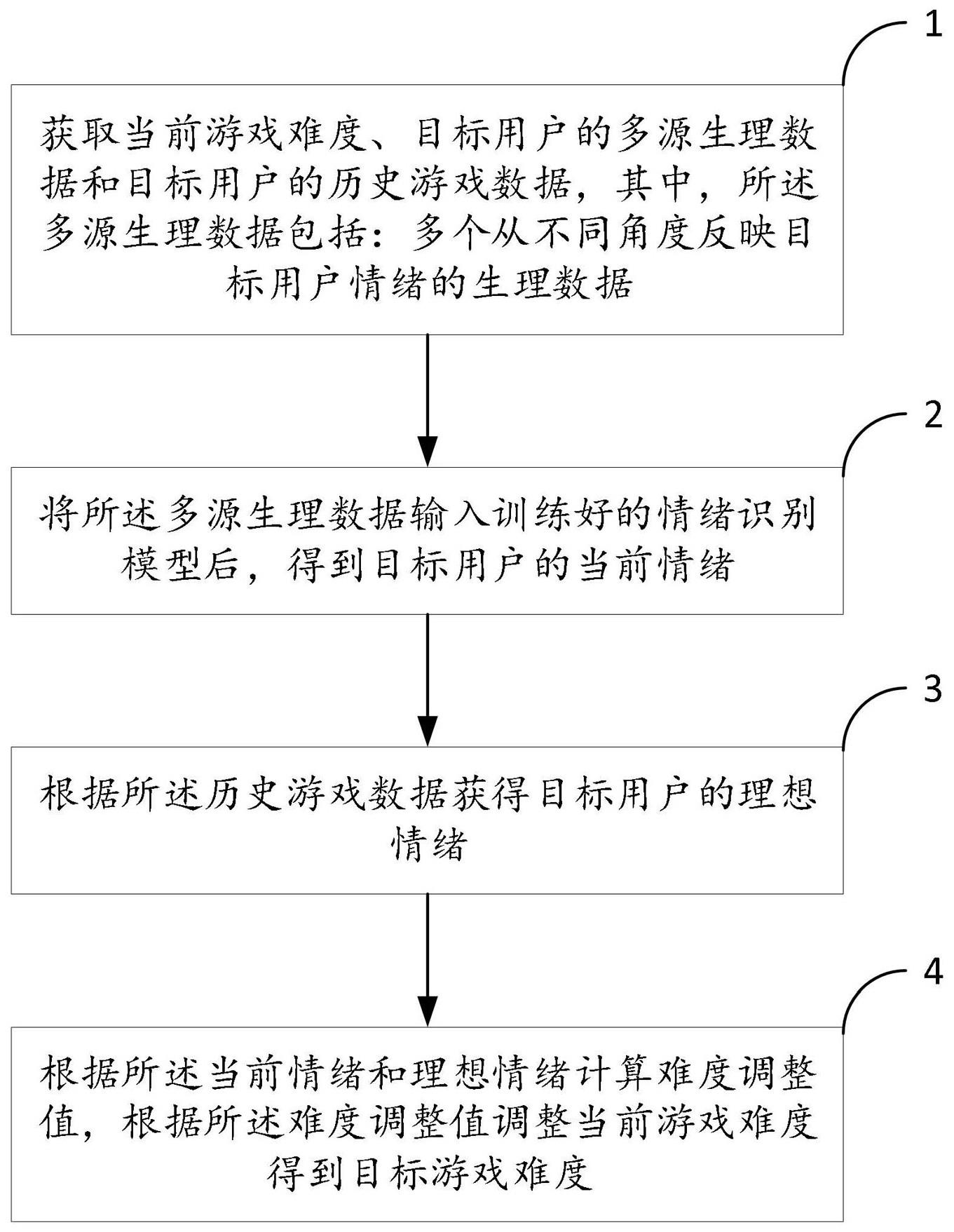
6.本发明第一方面公开了一种基于情绪识别的游戏难度调节方法,其特征在于,包括:获取当前游戏难度、目标用户的多源生理数据和目标用户的历史游戏数据,其中,所述多源生理数据包括:多个从不同角度反映目标用户情绪的生理数据;将所述多源生理数据输入训练好的情绪识别模型后,得到目标用户的当前情绪;根据所述历史游戏数据获得目标用户的理想情绪;根据所述当前情绪和理想情绪计算难度调整值,根据所述难度调整值调整当前游戏难度得到目标游戏难度。
7.可选的,所述情绪识别模型包括:多个与多个所述生理数据一一对应的lstm网络,用于提取对应的生理数据的特征向量;多源融合网络,用于将所有生理数据对应的特征向量进行拼接得到多源特征向量,提取所述多源特征向量的多源情感特征,根据所述多源情感特征预测得到目标用户的
当前情绪。
8.可选的,所述根据所述历史游戏数据获得目标用户的理想情绪,包括:采用预设滑动窗口对所述历史游戏数据进行分割,对分割后的历史游戏数据使用onehot编码得到编码数据,对所述编码数据提取时间统计特征;将所述时间统计特征输入训练好的用户情感分类模型中得到所述目标用户的目标情感类别及对应的目标情感值;根据所述目标情感类别从多个预设情感函数中选取对应的目标情感函数,其中,所述目标情感函数的自变量为游戏难度,因变量为情感预测值;初始化第一参数对所述目标情感函数进行调整得到优化目标函数,将所述目标情感值和优化目标函数在当前游戏难度下的情感预测值输入预设目标函数得到输出值,根据所述输出值更新第一参数,进行多次迭代,直至预设目标函数收敛,将预设目标函数收敛后对应的第一参数带入优化目标函数得到最优目标情感函数;将所述最优目标情感函数在当前游戏难度下的情感预测值作为目标用户的理想情绪。
9.可选的,所述用户情感分类模型的训练方法,包括:收集不同用户的游戏数据,对不同用户的游戏数据进行预处理,形成样本集;采用所述样本集对用户情感分类模型进行训练,使用预设损失函数计算预测误差,通过反向传播算法更新用户情感分类模型的参数,直至收敛,得到训练好的用户情感分类模型;所述预设损失函数为:loss = mse(y_pred, y_true) ce(p(y|y_pred), y_true),其中,所述y_pred为用户情感分类模型根据输入预测的用户的预测情感类别概率,y_true为样本集中的样本对应的真实情感类别,mse代表均方误差损失,用于衡量y_pred和 y_true之间的差异,p(y|y_pred)是用户情感分类模型预测情感分类的概率分布,ce代表交叉熵损失,用于评估y_pred和 y_true的差异。
10.可选的,所述预设情感函数的构建方法包括:收集不同用户的游戏数据,对不同用户的游戏数据进行预处理,形成样本集;将所述样本集中的样本输入训练好的用户情感分类模型得到各个用户对应的情感类别,根据所述情感类别对所有用户进行初始分类,通过聚类算法对初始分类后的用户重新进行分类得到多个簇;获取所述样本集中的各个用户在不同游戏难度下的情感值;在所述样本集中的各个用户对应的情感值与游戏难度上,利用回归算法拟合所述样本集中的各个用户对应的个体情感响应曲线,根据各个所述个体情感相应曲线计算得到样本集中各个用户在各个游戏难度下的情感值;根据所述样本集中各个用户在各个游戏难度下的情感值计算各个簇在各个游戏难度下的平均情感值,在各个所述簇对应的平均情感值与游戏难度上,利用回归算法拟合各个所述簇对应的平均情感响应曲线,利用预设的第二参数对各个平均情感响应曲线进行调整,得到各个簇对应的预设情感函数。
11.可选的,所述根据所述当前情绪和理想情绪计算难度调整值,包括:
计算所述当前情绪与理想情绪之间的情绪差值;在所述情绪差值大于上限阈值,且持续时间超过第一预设时间的情况下,以及在所述情绪差值小于下限阈值,且持续时间超过第二预设时间的情况下,通过难度调整公式计算难度调整值;所述难度调整公式为:,,其中,所述k(u) 表示用户情感类别系数,k表示根据用户情感类别u采用不同的系数,err表示情绪差值,表示时间衰减因子,实现难度调整的衰减效果,t表示用户情感类别u对应的衰减时间常数,控制衰减速率,t表示时间,a 表示映射上限,b表示映射的增长速率,c表示映射的中间点。
12.可选的,在所述获取当前游戏难度之前,包括:根据游戏需求和机制,确定影响难度的关键参数;对各个所述关键参数,设定多个参数值,将所有关键参数中的参数值进行排列组合,组成不同游戏难度的多个参数组合;测试各个所述参数组合的难易程度,确定各个参数组合的游戏难度;根据各个参数组合对应的参数值和对应的游戏难度,构建关键参数与游戏难度的映射表。
13.本发明第二方面公开了一种基于情绪识别的游戏难度调节系统,包括:数据获取模块,用于获取当前游戏难度、目标用户的多源生理数据和目标用户的历史游戏数据,其中,所述多源生理数据包括:多个从不同角度反映目标用户情绪的生理数据;当前情绪模块,用于将所述多源生理数据输入训练好的情绪识别模型后,得到目标用户的当前情绪;理想情绪模块,用于根据所述历史游戏数据获得目标用户的理想情绪;难度调整模块,用于根据所述当前情绪和理想情绪计算难度调整值,根据所述难度调整值调整当前游戏难度得到目标游戏难度。
14.本发明第三方面公开了一种计算机设备, 包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述的方法的步骤。
15.本发明第四方面公开了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述的方法的步骤。
16.本发明所提供的技术方案具有以下的优点及效果:通过目标用户的多源生理数据准确获取目标用户的当前情绪,然后计算目标用户的理想情绪,根据当前情绪和理想情绪计算难度调整值实现个性化的难度调节,可以保持目标用户处于最佳情绪状态,避免由于情绪波动产生的负面游戏体验,从而提高用户的游戏满意度;通过用户情感分类模型和预设情感函数的建立,可以针对不同类型用户进行精准情感判断,从而实现个性化的难度调节,不同用户可以获得符合自身情感模式的游戏体验。
附图说明
17.图1是本发明实施例公开的基于情绪识别的游戏难度调节方法的流程示意图;图2是本发明实施例公开的基于情绪识别的游戏难度调节系统的结构框图;图3是本发明实施例中公开的计算机设备的内部结构图。
具体实施方式
18.为了便于理解本发明,下面将参照说明书附图对本发明的具体实施例进行更详细的描述。
19.除非特别说明或另有定义,本文所使用的“第一、第二
…”
仅仅是用于对名称的区分,不代表具体的数量或顺序。
20.除非特别说明或另有定义,本文所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
21.需要说明的是,本文中“固定于”、“连接于”,可以是直接固定或连接于一个元件,也可以是间接固定或连接于一个元件。
22.如图1所示,本发明实施例公开了一种基于情绪识别的游戏难度调节方法,包括:步骤1、获取当前游戏难度、目标用户的多源生理数据和目标用户的历史游戏数据,其中,所述多源生理数据包括:多个从不同角度反映目标用户情绪的生理数据。
23.具体地,多源生理数据包括:目标用户在游戏过程中所采集的脑电数据、面部表情数据和语音数据等;脑电数据能够采用脑电头环采集电极,采集频率可设置为500hz;面部表情数据使用rgb摄像头,采集面部表情图像,定位眉毛、眼睛和嘴部的关键点,提取形状和表情变化信息,采集频率为30hz;语音数据能够通过麦克风,采集语音声音信号,采样频率设为16khz,进行消噪处理后,提取语音特征如音高、语调等;通过发送同步触发指令,确保脑电数据、面部表情数据和语音数据时间对齐采集,如设定一个主控制模块,向所有采集设备发送同步采集的触发指令,触发指令包含精确的时间戳信息,如gps时间、网络时间等,各采集设备接收到指令后,记录当前时间与触发时间的偏移量,根据该偏移量,调整采集开始时间,使各设备同步开始采集,也可以在数据存储时,将时间戳偏移量记录在数据标签中,后续处理时将数据按时间标签对齐,无需考虑设备之间的时间偏差,整个同步过程精度可以达到毫秒级别。
24.在实际应用中,还能够将采集的脑电数据、面部表情数据和语音数据等多源生理数据进行统一格式化排序,然后进行标注、存档。具体地,对多源生理数据进行格式校验、去噪、插值、归一化等预处理,将预处理后的多源生理数据转换为统一的数字矩阵格式,方便存储和处理,如脑电数据转换为(通道数
×
采样点数)的矩阵。
25.在获取当前游戏难度之前,包括:根据游戏需求和机制,确定影响难度的关键参数;其中,所述关键参数通常包括:玩家生命值、敌人数量、玩家攻击力、敌人移动速度、物品出现概率、过关时间限制等,根据游戏需求和机制的不同,选取不同的关键参数。
26.对各个所述关键参数,设定多个参数值,将所有关键参数中的参数值进行排列组合,组成不同游戏难度的多个参数组合;在本实施例中,如关键参数为生命值和敌人数量,为生命值和敌人数量设定多个参数值,如生命值:100、80、60、40、20,敌人数量:5、10、15、
20、30,将所有关键参数中的参数值进行排列组合,如得到不同游戏难度的生命值100、敌人数量5的参数组合,生命值100、敌人数量10的参数组合
…
生命值20、敌人数量30的参数组合。
27.测试各个所述参数组合的难易程度,确定各个参数组合的游戏难度;在实际应用中,得到不同游戏难度的多个参数组合后,能够邀请有代表性的玩家进行游戏测试,让玩家在不同参数组合下尝试游戏,根据游戏时间、过关率、生命值剩余等客观指标评估难易度,能够通过问卷形式获得玩家的主观反馈,统计各个参数组合的客观指标和主观反馈,确定参数组合对应的难度级别,能够重复测试,收集更多数据,优化级别划分,使其能够有效反映游戏难度。
28.根据各个参数组合对应的参数值和对应的游戏难度,构建关键参数与游戏难度的映射表。在本实施例中,映射表的横轴为参数值,纵轴为游戏难度,建立二维映射关系。除了设定固定的几个游戏难度之外,可以在游戏难度之间插入更多中间值。例如生命值,除了[100,80,60,40,20]之外,还可以插入[90,70,50,30]等中间值,通过插值算法,可以得到参数值在整个取值范围内与游戏难度的映射函数关系,假设参数值的取值范围为[x_min,x_max],对应游戏难度的范围[y_min,y_max],则参数x与难度y之间的映射函数可以采用线性插值公式:,其中,x 表示当前的参数值,y表示当前的参数值对应的游戏难度;如,生命值范围[0,100] 映射到难度范围[1,10],当生命值x=80时,,通过线性插值公式,可以建立参数值到游戏难度的连续映射关系,从而实现平滑调节难度的效果。
[0029]
步骤2、将所述多源生理数据输入训练好的情绪识别模型后,得到目标用户的当前情绪。在本实施例中,得到目标用户的当前情绪后,能够将该当前情绪映射到连续情绪值,具体地,如果表示正面情绪程度最大的值设为1,表示负面情绪程度最大的值设为-1,在将多源生理数据输入训练好的情绪识别模型后得到目标用户属于正面、中性、负面情绪的概率为(0.7,0.1,0.2),其中最大概率0.7对应的是正面情绪,所以判定该目标用户的当前情绪为正面情绪,0.7为目标用户的当前情绪概率值,为了得到一个连续值表示情绪强度,将其映射到[-1,1]区间,能够使用线性映射方式:,其中,0.5是中间值,2是缩放系数,在其他实施例中,中间值和缩放系数能够根据实际情况进行调整。在当前情绪概率值为0.7的情况下,,即目标用户的正面情绪强度值为0.4。
[0030]
在本实施例中,所述情绪识别模型包括:多个与多个所述生理数据一一对应的lstm网络,用于提取对应的生理数据的特征向量;lstm(long short term memory,长短期记忆)是一种特殊的递归神经网络;在有脑电数据、面部视频数据和语音数据这三个生理数据的情况下,则具有与脑电数据对应的脑电lstm网络、与面部视频数据对应的面部lstm网络、与语音数据对应的语音lstm网络;各个脑电lstm网络、面部lstm网络和语音lstm网络均具有第一输入层、多隐藏层和第一输出层,脑
电lstm网络的第一输入层节点数为脑电数据的特征维度,多隐藏层为多个lstm模块叠加,各个lstm模块处理一个时间步的数据,提取时序特征,然后经过第一输出层的向量化,得到定长的脑电数据对应的特征向量;面部lstm网络的第一输入层节点数为面部视频数据的特征维度,多隐藏层为多个lstm模块叠加,各个lstm模块处理一个时间步的数据,提取时序特征,然后经过第一输出层的向量化,得到定长的面部视频数据对应的特征向量;语音lstm网络的第一输入层节点数为语音数据的特征维度,多隐藏层为多个lstm模块叠加,各个lstm模块处理一个时间步的数据,提取时序特征,然后经过第一输出层的向量化,得到定长的语音数据对应的特征向量。
[0031]
多源融合网络,用于将所有生理数据对应的特征向量进行拼接得到多源特征向量,提取所述多源特征向量的多源情感特征,根据所述多源情感特征预测得到目标用户的当前情绪。
[0032]
具体地,所述多源融合网络包括:拼接层,用于将所有生理数据对应的特征向量进行拼接得到多源特征向量,如将脑电数据对应的特征向量、面部视频数据对应的特征向量和语音数据对应的特征向量依次拼接得到多源特征向量。
[0033]
全连接层,用于提取所述多源特征向量的多源情感特征,所述全连接层包括多个节点,该节点的数量通常按照特征向量长度的2-4倍来设置,全连接层可以学习多源特征向量之间的非线性组合关系,提取多源情感特征,能够在全连接层使用relu等激活函数引入非线性,还能采用dropout技术随机丢弃节点,防止过拟合,dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。
[0034]
第一输出层,用于根据所述多源情感特征预测得到目标用户的当前情绪,包含3个节点,分别代表正面情绪、中性情绪和负面情绪的概率。通过softmax函数,可以将第一输出层的原始值转换为归一化的概率分布,softmax能够映射任意实数到(0,1)区间,并满足概率的性质,使得3个节点的输出值和为1,均在0到1范围内,表示概率。
[0035]
在构建好情绪识别模型后,还需要对情绪识别模型进行训练,具体的训练方法包括:收集标注有真实情绪标签的多源训练数据集,多源训练数据集包括脑电数据、面部视频数据、语音数据等多个生理数据。具体地,对各个生理数据按时间顺序进行排序,确保各生理数据时间对齐,邀请标注人员,在游戏关键时刻手动添加情绪标签,标注数据,得到标注有真实情绪标签的生理数据,将生理数据和对应的标签一起,存入云端数据库中。
[0036]
定义情绪识别模型的损失函数,比如交叉熵损失,用来衡量情绪识别模型预测结果和真实标签的差距。进行多次迭代训练,在训练过程中,反向传播算法根据损失函数的梯度,迭代更新模型参数。通过多轮的梯度下降,逐步优化参数,使损失函数的值降低,情绪识别模型预测结果逼近真实标签。
[0037]
在对情绪识别模型进行训练的过程中,每隔预设轮数对使用验证集对情绪识别模型进行测试,所述验证集为不同用户的标注有真实情绪标签的多源生理数据,便于训练时监控多源训练数据集和验证集上损失函数的变化情况,当多源训练数据集损失继续下降而验证集损失开始上升时,说明情绪识别模型开始过拟合。通过优化训练轮数、正则化、提前停止训练等技术控制过拟合,得到在验证集上效果较好的情绪识别模型,完成对多源情绪
特征的融合与判断,最后在独立的测试集上评估模型的最终性能,测试集为不同用户的标注有真实情绪标签的多源生理数据,多源训练数据集、验证集和测试集中的生理数据各不相同。
[0038]
步骤3、根据所述历史游戏数据获得目标用户的理想情绪。
[0039]
在本实施例中,所述根据所述历史游戏数据获得目标用户的理想情绪,包括:采用预设滑动窗口对所述历史游戏数据进行分割,对分割后的历史游戏数据使用onehot编码得到编码数据,对所述编码数据提取时间统计特征;其中,所述历史游戏数据包括:操作序列、关卡特征等,其中,操作序列反映用户的控制习惯,包含用户的至少一基本操作,如移动、跳跃、攻击等基本操作,并记录各个基本操作对应的时刻和操作参数(如跳跃高度),关卡特征可以反映用户对不同难度关卡的适应性,包含每关的基本信息,如难度系数、关卡元素配置等,并记录用户在每关的通过次数、失败次数、完成用时。假设目标用户的操作序列为:[跳跃,移动,攻击,跳跃,跳跃,移动,攻击,移动] ,可以采用固定长度为3的滑动窗口进行分割,窗口重叠大小为2,则可以得到:[跳跃,移动,攻击]、[移动,攻击,跳跃]、[攻击,跳跃,跳跃]、[跳跃,跳跃,移动]、[跳跃,移动,攻击]、[移动,攻击,移动],然后对每个基本操作使用onehot编码,例如跳跃编码为[1,0,0],移动编码为[0,1,0],攻击编码为[0,0,1],便于提取出以下时间统计特征:一、操作次数:跳跃7次,移动6次,攻击5次;二、操作持续时间:计算各个基本操作的持续窗口数,跳跃3窗口,移动2窗口,攻击2窗口;三、操作频率:跳跃在80%的窗口有出现,移动在80%的窗口有出现,攻击在80%的窗口有出现。
[0040]
通过对操作序列的分割、编码和特征提取,目标用户的操作行为模式可以有效地表达出来,使得目标用户的复杂游戏行为被转换成算法可识别的特征表达形式。
[0041]
将所述时间统计特征输入训练好的用户情感分类模型中得到所述目标用户的目标情感类别及对应的目标情感值。
[0042]
在本实施例中,所述用户情感分类模型也是基于lstm网络构建,包括:第二输入层、lstm层和第二输出层;第二输入层用于接收预处理后的游戏数据,如操作序列的编码向量和时间统计特征,以将离散的游戏数据转换成用户情感分类模型可以处理的张量格式;lstm层用于捕捉操作序列中的长期依赖关系,学习用户的行为模式,lstm层通过遗忘门、输入门、输出门来控制信息的流动,遗忘门、输入门、输出门的计算公式如下:遗忘门计算公式:,输入门计算公式:,输出门计算公式:,细胞状态通过遗忘门和输入门来更新,更新公式如下:,最终的lstm层输出为:,
其中,表示输入,表示上一时刻的输出,wf表示遗忘门的权重向量,bf表示遗忘门的偏置向量,wi表示输入门的权重向量,bi表示输入门的偏置向量,wo表示输出门的权重向量,bo表示输出门的偏置向量,wc表示细胞状态的权重向量,bc表示细胞状态的偏置向量,表示sigmoid激活函数。wf、bf、wi、bi、wo、bo、wc、bc都是用户情感分类模型需要学习的参数,通常会随机初始化,然后在训练过程中通过反向传播算法逐步调整,使模型对输入到输出的映射关系误差最小化。具体的初始化方法有:使用均匀分布或高斯分布随机初始化权重向量,将偏置向量初始化为全0或很小的常数在用户情感分类模型训练过程中,这些参数会被优化,使用户情感分类模型能够捕捉时间序列数据中的长期依赖,实现对用户行为模式到情感的有效建模。
[0043]
所述用户情感分类模型的训练方法,包括:收集不同用户的游戏数据,对不同用户的游戏数据进行预处理,形成样本集;采用所述样本集对用户情感分类模型进行训练,使用预设损失函数计算预测误差,通过反向传播算法更新用户情感分类模型的参数,直至收敛,得到训练好的用户情感分类模型;所述预设损失函数为:loss = mse(y_pred, y_true) ce(p(y|y_pred), y_true),其中,所述y_pred为用户情感分类模型根据输入预测的用户的预测情感类别概率,y_true为样本集中的样本对应的真实情感类别,mse代表均方误差损失,用于衡量y_pred和 y_true之间的差异,p(y|y_pred)是用户情感分类模型预测情感分类的概率分布,ce代表交叉熵损失,用于评估y_pred和 y_true的差异。
[0044]
在本实施例中,通过将不同用户的游戏数据输入用户情感分类模型,使得用户情感分类模型学习到不同用户行为模式的特征,例如,频繁攻击可能反映负面的用户情感类别,保守操作则表示中性的用户情感类别。mse可以很好地捕捉连续情感值的变化趋势;ce可以有效地惩罚分类错误,提升分类效果,通过mse和ce,使得用户情感分类模型可以同时适合表示连续情感和区分离散情感分类,可以增强模型的预测能力。在本实施例中通过adam优化器更新参数,以最小化损失函数,adam优化器的公式如下:,,,其中,表示梯度gt的一阶矩估计,表示梯度gt的二阶矩估计,表示第一滑动平均系数,表示第二滑动平均系数,是学习率,避免分母为0。通过迭代地计算梯度的统计量,并应用自适应学习率,adam可以有效地更新wf、bf、wi、bi、wo、bo、wc、bc以及全连接层的权重矩阵和偏置向量,实现模型训练。
[0045]
根据所述目标情感类别从多个预设情感函数中选取对应的目标情感函数,其中,所述目标情感函数的自变量为游戏难度,因变量为情感预测值;初始化第一参数对所述目标情感函数进行调整得到优化目标函数,将所述目标情感值和优化目标函数在当前游戏难度下的情感预测值输入预设目标函数得到输出值,根据
所述输出值更新第一参数,进行多次迭代,直至预设目标函数收敛,将预设目标函数收敛后对应的第一参数带入优化目标函数得到最优目标情感函数;将所述最优目标情感函数在当前游戏难度下的情感预测值作为目标用户的理想情绪。
[0046]
在本实施例中,所述预设情感函数的构建方法包括:收集不同用户的游戏数据,对不同用户的游戏数据进行预处理,形成样本集;将所述样本集中的样本输入训练好的用户情感分类模型得到各个用户对应的情感类别,根据所述情感类别对所有用户进行初始分类,从标记了相同情感类别的用户行为数据中,提取表示用户游戏行为特征的变量,作为聚类算法的输入,如操作频率、完成难关用时、失败次数等,为了不同特征尺度一致,对提取的表示用户游戏行为特征的变量进行数据标准化处理,如将特征值处理为标准偏差为1,平均值为0的正态分布,然后通过聚类算法对初始分类后的用户重新进行分类得到多个簇,可以采用k-means聚类算法,具体地,在本实施例中分为三个簇:正面型用户,其操作频繁,用时短,失败少;中性型用户,其操作频率一般,用时和失败次数适中;负面型用户,其操作不频繁,完成难关用时长,失败次数多。
[0047]
获取所述样本集中的各个用户在不同游戏难度下的情感值;如用户a在不同游戏难度下的情感值为(game_parami, pi),1≤i≤n,game_parami表示游戏难度,pi表示情感值,具体地,调节游戏难度参数以调节游戏难度,调节游戏难度包括:提高/降低关卡难度系数、改变关卡配置等,然后将各个用户在不同游戏难度下的游戏数据输入用户情感分类模型,得到对应的情感类别及对应的情感值,将各个用户在不同游戏难度下的情感值映射到二维空间,横轴是game_param,纵轴是对应的情感值p。
[0048]
在所述样本集中的各个用户对应的情感值与游戏难度上,利用回归算法拟合所述样本集中的各个用户对应的个体情感响应曲线f(p|game_params),如使用简单的线性回归,得到线性响应曲线,也可以用高阶多项式曲线拟合,或者使用神经网络拟合复杂非线性响应曲线;根据各个所述个体情感相应曲线计算得到样本集中各个用户在各个游戏难度下的情感值;根据所述样本集中各个用户在各个游戏难度下的情感值计算各个簇在各个游戏难度下的平均情感值,在各个所述簇对应的平均情感值与游戏难度上,利用回归算法拟合各个所述簇对应的平均情感响应曲线,f_negative(p | game_params)、f_neutral(p | game_params)和f_positive(p | game_params),利用预设的第二参数对各个平均情感响应曲线进行调整,得到各个簇对应的预设情感函数,如负面型对应的预设情感函数为:,中性型对应的预设情感函数为:,其中,1.2、0.8和0.1为预设的第二参数,1.2和0.8是缩放系数,用于放大或缩小平均情感响应曲线的幅度,0.1是平移量,用于整体移动平均情感响应曲线的位置。通过 放大或缩小幅度,以适应不同类型用户的响应曲线幅度差异,通过平移位置,使计算得到的情感预测值处在合理的区间内,在其他实施例中,具体数值1.2和0.8可以增大或减小约20%的幅
度,0.1也能够根据实际需求进行调整。
[0049]
在本实施例中,预设目标函数设为:,其中,表示优化目标函数,p_type表示目标情感值;第一参数包括参数a和b,使用第一参数对目标情感函数e0_type进行调整得到优化目标函数:,其中,a和b的值能够通过优化算法(如梯度下降)迭代确定,以最小化预设目标函数,在迭代过程中,不断调整a和b,使逼近p_type。当预设目标函数收敛时,获得最终的a和b,将优化得到的参数a和b带入优化目标函数,得到最优目标情感函数,该最优目标情感函数在当前游戏难度下的情感预测值为目标用户的理想情绪。
[0050]
步骤4、根据所述当前情绪和理想情绪计算难度调整值,根据所述难度调整值调整当前游戏难度得到目标游戏难度。
[0051]
在本实施例中,所述根据所述当前情绪和理想情绪计算难度调整值,包括:计算所述当前情绪与理想情绪之间的情绪差值;在所述情绪差值大于上限阈值,且持续时间超过第一预设时间的情况下,以及在所述情绪差值小于下限阈值,且持续时间超过第二预设时间的情况下,通过难度调整公式计算难度调整值;所述难度调整公式为:,,其中,所述k(u) 表示用户情感类别系数,k表示根据用户情感类别u采用不同的系数,err表示情绪差值,表示时间衰减因子,实现难度调整的衰减效果,t表示用户情感类别u对应的衰减时间常数,控制衰减速率,t表示时间,a 表示映射上限,b表示映射的增长速率,c表示映射的中间点。
[0052]
具体地,中性型用户k取较小值,调整量相对较缓,负面型用户k取较大值,调整量更剧烈,k的取值能够通过训练学习获得,目标是针对不同用户达到最佳的难度调整效果,在当前情绪大于理想情绪的情况下,表示需要增加游戏难度,在当前情绪等于理想情绪的情况下,表示不需要调整游戏难度,在当前情绪小于理想情绪的情况下,表示需要降低游戏难度,通过时间衰减因子的设置,可以使游戏参数随时间衰减,逐渐返回原设置,以防止游戏参数永远保持在调整后的参数值,实现动态调节难度后回归的效果;上限阈值设为0.2,下限阈值设为-0.2,第一预设时间和第二预设时间相同,都为60秒,在其他实施例中,上限阈值、下限阈值、第一预设时间和第二预设时间能够根据实际需求进行调整,第一预设时间和第二预设时间可不同。在是本实施例中当err》0.2(上限阈值),且持续时间超过60秒时,表示目标用户的情绪值已经明显高于理想情绪,则计算s值,同时触发增加游戏难度的调整,当err《-0.2(下限阈值),且持续时间超过90秒时,表示目标用户的情绪值明显低于理想情绪,则计算s值,同时触发降低游戏难度的调整,通过上限阈值、下限阈值、第一预设时间
和第二预设时间的设置,能避免过于敏感的触发游戏难度调整。
[0053]
具体地,计算目标游戏难度level_targe = 难度调整值s 当前游戏难度level,在游戏参数和游戏难度的映射表中,查找级别为level_targe对应的游戏参数设置,获取该游戏参数设置,作为新的游戏参数动态平滑加载到游戏中,调整游戏难度至level_targe,如当前游戏难度level = 5,难度调整值s = 2,则目标游戏难度level_targe = s level = 2 5 = 7,在映射表中查找难度级别7的参数设置:生命值 60,攻击力10,将生命值60和攻击力10作为新的游戏参数将游戏难度调整至7。
[0054]
在本实施例中,还能设置冷却时间,在每次触发游戏难度调整后,会启动一个冷却计时器,时长设为120秒,在该120秒内,将不考虑新的游戏难度调整请求,冷却时间过后,才会再次检测是否满足触发条件,可以防止在短时间内触发多次游戏难度调整,在其他实施例中冷却计时器的时长能够根据实际需求进行调整。
[0055]
本发明实施例公开的基于情绪识别的游戏难度调节方法,通过目标用户的多源生理数据准确获取目标用户的当前情绪,然后计算目标用户的理想情绪,根据当前情绪和理想情绪计算难度调整值实现个性化的难度调节,可以保持目标用户处于最佳情绪状态,避免由于情绪波动产生的负面游戏体验,从而提高用户的游戏满意度;通过用户情感分类模型和预设情感函数的建立,可以针对不同类型用户进行精准情感判断,从而实现个性化的难度调节,不同用户可以获得符合自身情感模式的游戏体验;通过游戏参数与游戏难度的映射,可以实现平滑连续的难度调节,防止由于不合理参数产生的突兀体验,用户可以得到更流畅自然的游戏过程;通过映射表的设置,可以快速查找对应游戏难度的游戏参数组合,缩短设计和测试游戏难度的时间周期。
[0056]
如图2所示,本发明实施例公开了一种基于情绪识别的游戏难度调节系统,包括:数据获取模块10,用于获取当前游戏难度、目标用户的多源生理数据和目标用户的历史游戏数据,其中,所述多源生理数据包括:多个从不同角度反映目标用户情绪的生理数据;当前情绪模块20,用于将所述多源生理数据输入训练好的情绪识别模型后,得到目标用户的当前情绪;理想情绪模块30,用于根据所述历史游戏数据获得目标用户的理想情绪;难度调整模块40,用于根据所述当前情绪和理想情绪计算难度调整值,根据所述难度调整值调整当前游戏难度得到目标游戏难度。
[0057]
关于基于情绪识别的游戏难度调节系统的具体构成可以参见上文中对于基于情绪识别的游戏难度调节方法的构成,在此不再赘述。上述基于情绪识别的游戏难度调节系统的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
[0058]
在一个实施例中,提供了一种计算机设备,该计算机设备可以是服务器,其内部结构图可以如图3所示。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算
机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种基于情绪识别的游戏难度调节方法。
[0059]
本领域技术人员可以理解,图3中示出的结构,仅仅是与本技术方案相关的部分结构的框图,并不构成对本技术方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
[0060]
在一个实施例中,提供了一种计算机设备, 包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行计算机程序时实现以下步骤:获取当前游戏难度、目标用户的多源生理数据和目标用户的历史游戏数据,其中,所述多源生理数据包括:多个从不同角度反映目标用户情绪的生理数据;将所述多源生理数据输入训练好的情绪识别模型后,得到目标用户的当前情绪;根据所述历史游戏数据获得目标用户的理想情绪;根据所述当前情绪和理想情绪计算难度调整值,根据所述难度调整值调整当前游戏难度得到目标游戏难度。
[0061]
在一个实施例中,所述情绪识别模型包括:多个与多个所述生理数据一一对应的lstm网络,用于提取对应的生理数据的特征向量;多源融合网络,用于将所有生理数据对应的特征向量进行拼接得到多源特征向量,提取所述多源特征向量的多源情感特征,根据所述多源情感特征预测得到目标用户的当前情绪。
[0062]
在一个实施例中,所述根据所述历史游戏数据获得目标用户的理想情绪,包括:采用预设滑动窗口对所述历史游戏数据进行分割,对分割后的历史游戏数据使用onehot编码得到编码数据,对所述编码数据提取时间统计特征;将所述时间统计特征输入训练好的用户情感分类模型中得到所述目标用户的目标情感类别及对应的目标情感值;根据所述目标情感类别从多个预设情感函数中选取对应的目标情感函数,其中,所述目标情感函数的自变量为游戏难度,因变量为情感预测值;初始化第一参数对所述目标情感函数进行调整得到优化目标函数,将所述目标情感值和优化目标函数在当前游戏难度下的情感预测值输入预设目标函数得到输出值,根据所述输出值更新第一参数,进行多次迭代,直至预设目标函数收敛,将预设目标函数收敛后对应的第一参数带入优化目标函数得到最优目标情感函数;将所述最优目标情感函数在当前游戏难度下的情感预测值作为目标用户的理想情绪。
[0063]
在一个实施例中,所述用户情感分类模型的训练方法,包括:收集不同用户的游戏数据,对不同用户的游戏数据进行预处理,形成样本集;采用所述样本集对用户情感分类模型进行训练,使用预设损失函数计算预测误差,通过反向传播算法更新用户情感分类模型的参数,直至收敛,得到训练好的用户情感分类模型;所述预设损失函数为:loss = mse(y_pred, y_true) ce(p(y|y_pred), y_true),
其中,所述y_pred为用户情感分类模型根据输入预测的用户的预测情感类别概率,y_true为样本集中的样本对应的真实情感类别,mse代表均方误差损失,用于衡量y_pred和 y_true之间的差异,p(y|y_pred)是用户情感分类模型预测情感分类的概率分布,ce代表交叉熵损失,用于评估y_pred和 y_true的差异。
[0064]
在一个实施例中,所述预设情感函数的构建方法包括:收集不同用户的游戏数据,对不同用户的游戏数据进行预处理,形成样本集;将所述样本集中的样本输入训练好的用户情感分类模型得到各个用户对应的情感类别,根据所述情感类别对所有用户进行初始分类,通过聚类算法对初始分类后的用户重新进行分类得到多个簇;获取所述样本集中的各个用户在不同游戏难度下的情感值;在所述样本集中的各个用户对应的情感值与游戏难度上,利用回归算法拟合所述样本集中的各个用户对应的个体情感响应曲线,根据各个所述个体情感相应曲线计算得到样本集中各个用户在各个游戏难度下的情感值;根据所述样本集中各个用户在各个游戏难度下的情感值计算各个簇在各个游戏难度下的平均情感值,在各个所述簇对应的平均情感值与游戏难度上,利用回归算法拟合各个所述簇对应的平均情感响应曲线,利用预设的第二参数对各个平均情感响应曲线进行调整,得到各个簇对应的预设情感函数。
[0065]
在一个实施例中,所述根据所述当前情绪和理想情绪计算难度调整值,包括:计算所述当前情绪与理想情绪之间的情绪差值;在所述情绪差值大于上限阈值,且持续时间超过第一预设时间的情况下,以及在所述情绪差值小于下限阈值,且持续时间超过第二预设时间的情况下,通过难度调整公式计算难度调整值;所述难度调整公式为:,,其中,所述k(u) 表示用户情感类别系数,k表示根据用户情感类别u采用不同的系数,err表示情绪差值,表示时间衰减因子,实现难度调整的衰减效果,t表示用户情感类别u对应的衰减时间常数,控制衰减速率,t表示时间,a 表示映射上限,b表示映射的增长速率,c表示映射的中间点。
[0066]
在一个实施例中,在所述获取当前游戏难度之前,包括:根据游戏需求和机制,确定影响难度的关键参数;对各个所述关键参数,设定多个参数值,将所有关键参数中的参数值进行排列组合,组成不同游戏难度的多个参数组合;测试各个所述参数组合的难易程度,确定各个参数组合的游戏难度;根据各个参数组合对应的参数值和对应的游戏难度,构建关键参数与游戏难度的映射表。
[0067]
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算
机程序被处理器执行时实现以下步骤:获取当前游戏难度、目标用户的多源生理数据和目标用户的历史游戏数据,其中,所述多源生理数据包括:多个从不同角度反映目标用户情绪的生理数据;将所述多源生理数据输入训练好的情绪识别模型后,得到目标用户的当前情绪;根据所述历史游戏数据获得目标用户的理想情绪;根据所述当前情绪和理想情绪计算难度调整值,根据所述难度调整值调整当前游戏难度得到目标游戏难度。
[0068]
在一个实施例中,所述情绪识别模型包括:多个与多个所述生理数据一一对应的lstm网络,用于提取对应的生理数据的特征向量;多源融合网络,用于将所有生理数据对应的特征向量进行拼接得到多源特征向量,提取所述多源特征向量的多源情感特征,根据所述多源情感特征预测得到目标用户的当前情绪。
[0069]
在一个实施例中,所述根据所述历史游戏数据获得目标用户的理想情绪,包括:采用预设滑动窗口对所述历史游戏数据进行分割,对分割后的历史游戏数据使用onehot编码得到编码数据,对所述编码数据提取时间统计特征;将所述时间统计特征输入训练好的用户情感分类模型中得到所述目标用户的目标情感类别及对应的目标情感值;根据所述目标情感类别从多个预设情感函数中选取对应的目标情感函数,其中,所述目标情感函数的自变量为游戏难度,因变量为情感预测值;初始化第一参数对所述目标情感函数进行调整得到优化目标函数,将所述目标情感值和优化目标函数在当前游戏难度下的情感预测值输入预设目标函数得到输出值,根据所述输出值更新第一参数,进行多次迭代,直至预设目标函数收敛,将预设目标函数收敛后对应的第一参数带入优化目标函数得到最优目标情感函数;将所述最优目标情感函数在当前游戏难度下的情感预测值作为目标用户的理想情绪。
[0070]
在一个实施例中,所述用户情感分类模型的训练方法,包括:收集不同用户的游戏数据,对不同用户的游戏数据进行预处理,形成样本集;采用所述样本集对用户情感分类模型进行训练,使用预设损失函数计算预测误差,通过反向传播算法更新用户情感分类模型的参数,直至收敛,得到训练好的用户情感分类模型;所述预设损失函数为:loss = mse(y_pred, y_true) ce(p(y|y_pred), y_true),其中,所述y_pred为用户情感分类模型根据输入预测的用户的预测情感类别概率,y_true为样本集中的样本对应的真实情感类别,mse代表均方误差损失,用于衡量y_pred和 y_true之间的差异,p(y|y_pred)是用户情感分类模型预测情感分类的概率分布,ce代表交叉熵损失,用于评估y_pred和 y_true的差异。
[0071]
在一个实施例中,所述预设情感函数的构建方法包括:收集不同用户的游戏数据,对不同用户的游戏数据进行预处理,形成样本集;
将所述样本集中的样本输入训练好的用户情感分类模型得到各个用户对应的情感类别,根据所述情感类别对所有用户进行初始分类,通过聚类算法对初始分类后的用户重新进行分类得到多个簇;获取所述样本集中的各个用户在不同游戏难度下的情感值;在所述样本集中的各个用户对应的情感值与游戏难度上,利用回归算法拟合所述样本集中的各个用户对应的个体情感响应曲线,根据各个所述个体情感相应曲线计算得到样本集中各个用户在各个游戏难度下的情感值;根据所述样本集中各个用户在各个游戏难度下的情感值计算各个簇在各个游戏难度下的平均情感值,在各个所述簇对应的平均情感值与游戏难度上,利用回归算法拟合各个所述簇对应的平均情感响应曲线,利用预设的第二参数对各个平均情感响应曲线进行调整,得到各个簇对应的预设情感函数。
[0072]
在一个实施例中,所述根据所述当前情绪和理想情绪计算难度调整值,包括:计算所述当前情绪与理想情绪之间的情绪差值;在所述情绪差值大于上限阈值,且持续时间超过第一预设时间的情况下,以及在所述情绪差值小于下限阈值,且持续时间超过第二预设时间的情况下,通过难度调整公式计算难度调整值;所述难度调整公式为:,,其中,所述k(u) 表示用户情感类别系数,k表示根据用户情感类别u采用不同的系数,err表示情绪差值,表示时间衰减因子,实现难度调整的衰减效果,t表示用户情感类别u对应的衰减时间常数,控制衰减速率,t表示时间,a 表示映射上限,b表示映射的增长速率,c表示映射的中间点。
[0073]
在一个实施例中,在所述获取当前游戏难度之前,包括:根据游戏需求和机制,确定影响难度的关键参数;对各个所述关键参数,设定多个参数值,将所有关键参数中的参数值进行排列组合,组成不同游戏难度的多个参数组合;测试各个所述参数组合的难易程度,确定各个参数组合的游戏难度;根据各个参数组合对应的参数值和对应的游戏难度,构建关键参数与游戏难度的映射表。
[0074]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,
诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink) dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
[0075]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!