一种在自然环境中快速检测小麦赤霉病穗及严重度的方法-j9九游会真人
1.本发明涉及图像识别技术领域,具体为一种在自然环境中快速检测小麦赤霉病穗及严重度的方法。
背景技术:
2.小麦赤霉病(fusarium head blight,fhb)是小麦中最常见和最具破坏性的病害之一,对粮食安全和人类健康构成严重威胁。因此,实时检测和确定小麦fhb的严重程度对于有效管理和损失评估至关重要。目标检测为疾病检测提供了新的思路和方法。然而目前的大多数模型较为复杂,这极大地要求了硬件的计算能力和实现成本,限制了模型的部署和移植。因此,在轻量化的前提下对小麦fhb进行有效的实时检测和严重度评估至关重要。本研究提出了一种新颖先进yolov5s算法,该算法既能实现高精度,又能实现快速的检测,促进小麦fhb的快速准确检测。
技术实现要素:
3.针对现有技术的不足,本发明提供了一种在自然环境中快速检测小麦赤霉病穗及严重度的方法,解决了背景技术中所提出的问题。
4.为实现以上目的,本发明通过以下技术方案予以实现:一种在自然环境中快速检测小麦赤霉病穗及严重度的方法,所述步骤包括如下:
5.s1:使用改进的yolov5s网络检测田间小麦穗,以检测病穗和健康穗;
6.s2:将本研究提出的改进型yolov5s与yolov3-tiny、yolov4、ssd、faster r-cnn和yolov7模型进行了对比,验证了模型的有效性和优越性。
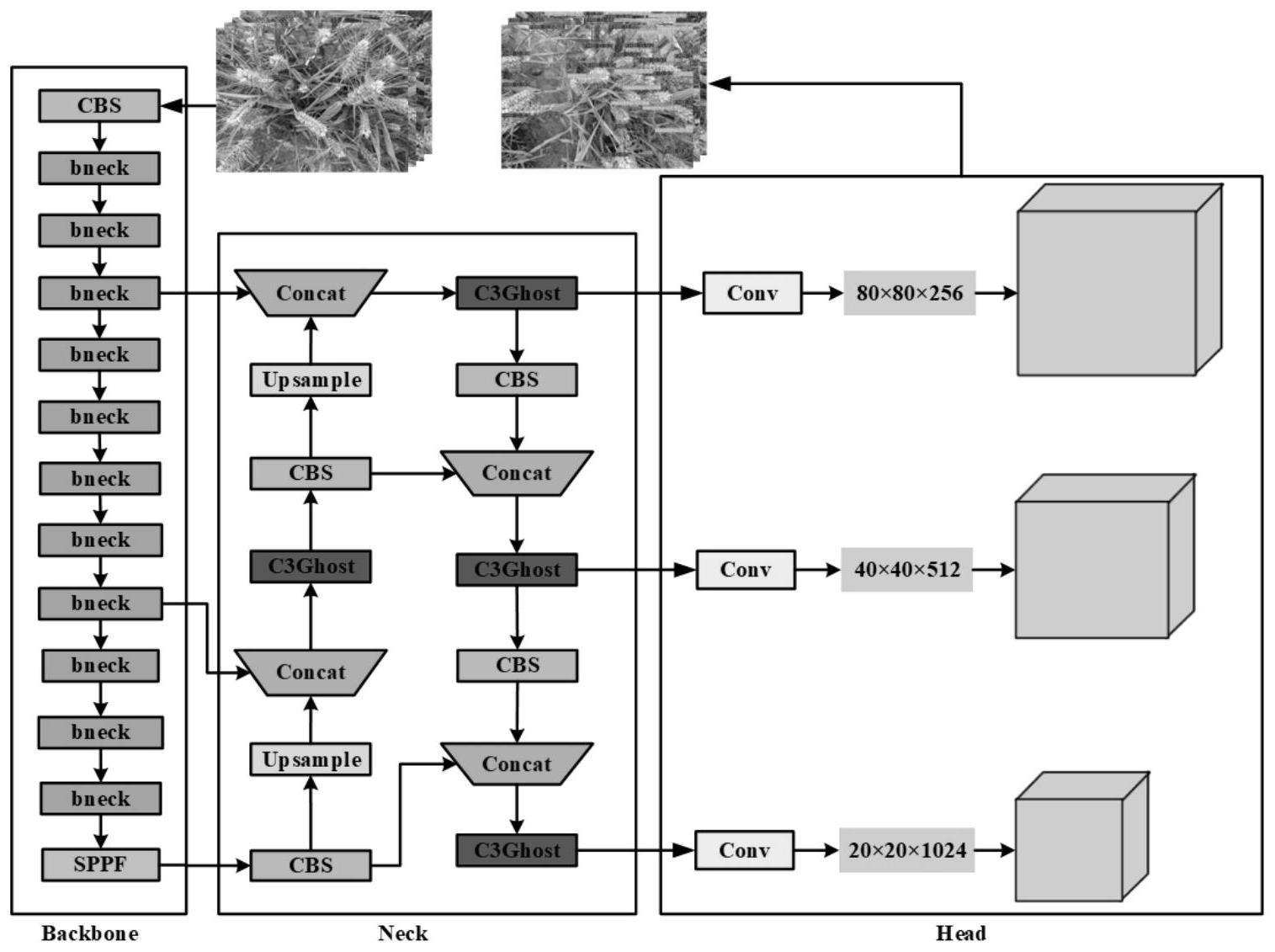
7.优选的,所述步骤s2中模型为yolov5s模型,所述yolov5是yolov4的改进版本,所述yolov5s模型是一个经典的单阶段结构(zang et al.,2022),它包括以下三部分:特征提取主干网络,特征融合颈部网络和检测头(t.jiang,li,yang,&wang,2022)yolov5s算法的检测过程包括以下三个主要步骤:
8.(1)特征提取:将输入图像的尺寸调整为640
×
640,并将调整后的图像输入主干网络,主干网络集成了卷积(convolution,conv),c3,快速空间金字塔池化(fast spatial pyramid pooling mudule,sppf)等多种特征提取模块;
9.(2)特征融合:主干网络生成的特征图传输到颈部网络,颈部网络采用panet结构进行多尺度特征融合,充分整合特征图提供的不同层和尺度的信息;
10.(3)检测头检测:在颈部网络中融合特征后,该层的输出被输送到用于不同尺度的目标的三个检测头,这些检测头可分别检测小型、中型和大型目标。
11.优选的,所述步骤s1中包括mobilenetv3主干网络,采用轻量级网络mobilenetv3替换了yolov5s的原始主干网络,将sppf模块整合到主干网络中,以增强感受野和特征表达能力,从而提高检测精度,此外,我们将颈部的c3模块替换为c3ghost模块,以进一步减小模型尺寸,所述mobilenetv3遵循mobilenetv1的深度可分离卷积和mobilenetv2的线性瓶颈
和倒残差结构,并通过网络架构搜索(neural architecture search,nas)获取参数,它使用netadapt算法来获得卷积内核和通道的最佳数量,此外,该模型在优化过程中引入了h-swish函数和挤压和激励(squeeze-and-excitation,se)模块,大大提高了模型的速度和性能;
12.h-swish是swish非线性的最新修改版本,与原始swish函数相比,其计算速度更快,对量化更友好。计算公式如下:
[0013][0014]
所述se是一种注意力机制,通过自适应地调整特征图中每个通道的权重来提高模型的表达能力,se架构包括两个主要模块:挤压模块和激励模块。挤压模块通过全局平均池化操作将特征图的空间维度降为1x1,得到每个通道的全局特征描述。激励模块利用全连接层来学习每个通道的重要性权重,然后将这些权重应用于原始特征图,生成加权特征图,随后转发到下一层进行处理;
[0015]
通过将注意力se模块插入到神经网络的不同层中,可以使网络更加关注重要的特征,减少对不重要特征的依赖,从而提高模型的性能和泛化能力。
[0016]
优选的,所述c3ghost是通过用ghost bottleneck替换原始的c3中的bottleneck来减少模型参数的引入的,ghost bottleneck包括ghostconv和深度卷积(depthwise convolution,dwconv),the ghost模块可以降低一般卷积层的计算复杂度,同时保持相似的识别性能(k.han et al.,2020;shang et al.,2023);
[0017]
优选的,所述步骤s2中还包括对模型的评估,利用多个指标来综合评估模型的性能,包括精度(precision,p)、召回率(recall,r)、f1得分、全类平均精度(mean average precision,map)、每秒帧数(frames per second,fps)、参数量(parameters)和每秒次浮点运算(flops),p反映模型对正样本进行分类的能力,r评估模型找到正样本s的能力,f1分数是p和r的调和平均值,map表示所有类别的平均精度的平均值,fps用于评估模型s的检测速度,此外,parameters用于衡量模型的大小,flops用于评估模型的计算复杂度,p、r、f1和map的计算方法如下:
[0018][0019][0020][0021][0022][0023]
其中tp表示正确检测到的正样本数,而fp表示错误检测到的正样本数,同样,tn表示正确检测到的正样本的数量,而fn表示错误检测到的负样本数,此外,n表示本研究中分析的数据类别的数量。
[0024]
优选的,所述步骤s1中还包括数据集的准备,为了满足对象检测的训练要求,使用
labelme获得了每个图像对应的标签文件,在图像中手动将小麦穗标记为两类:fhb和healthy,共生成402个标记文件,共标注16,884个小麦穗,平均每个图像包含42个小麦穗,随后对图像进行了离线增强和在线增强,操作分别为:离线增强使用组合增强来模拟自然环境中样品的复杂性,组合增强通过翻转(水平和垂直)、亮度变换、锐化、对比度变换、模糊(高斯模糊、平均模糊、中值模糊之一)、拉伸和失真,在图像上进行不重复的组合操作处理,将组合数量限制为至多四个;在线增强选择马赛克增强和混合增强等方式,以提高模型的鲁棒性,在线增强功能包括色彩空间变换、随机水平翻转、图像缩放、图像平移、马赛克增强和mixup增强;
[0025]
将增强的小麦图像以8:2的比例分为训练集和测试集,随后,训练集进一步分为训练集和验证集,比例为9:1,数据集包括1736张训练图像和193张验证图像以及483张测试图像,利用训练集训练模型,利用验证集来评估模型的泛化性,利用测试集来评估模型的准确性和鲁棒性,本步骤确保有足够的图像可用于训练、调整和测试模型。
[0026]
优选的,利用pytorch 1.10.0深度学习框架构建和改进模型,并在ubuntu 20.04下对模型进行训练和测试,计算机的cpu是amd epyc 7642 48核处理器,2.3ghz,具有80g内存,gpu是nvidia geforce rtx 3090,具有24g视频内存,为了加快网络训练速度,我们使用gpu进行加速,cuda版本11.3和cudnn版本8.2.1,在训练过程中采用sgd优化算法,将sgd动量参数统一设置为0.937,初始学习率设置为0.01,权重衰减参数设置为5e-4,采用图像加权策略改善样本数量的不平衡问题,使用余弦退火算法更新学习率,将输入图像的尺寸调整为640
×
640像素,bacth size大小设置为32,以满足每个模型的训练需求,训练批次(epoch)总数设置为500。
[0027]
优选的,通过消融实验以探索mobilenetv3和c3ghost模块对模型的影响,集成mobilenetv3和c3ghost模块足以保证准确性和速度(map=97.15%,fps=80),此外,与仅添加mobilenetv3(fps=71.93)相比,添加c3ghost模块可以进一步减小模型大小并加快检测速度(fps=80),值得注意的是,与原来的yolov5相比,所提出的模型的fps提高了10.5,参数数量减少了49.72%,flops减少了71.32%,确保所提出的模型具有最小的模型尺寸和最高的检测速度,不会影响检测的准确性。
[0028]
优选的,为了验证所提小麦fhb检测方法的有效性,比较了5种目标检测算法,包括yolov3-tiny、yolov4、ssd、faster r-cnn和yolov7,每个模型在相同的条件下进行训练和验证,网络训练周期为500,然后,使用测试集评估6种检测算法的性能,为了进一步验证改进的yolov5s的有效性,我们随机选择了一个图像并比较了不同模型的检测性能。
[0029]
优选的,为了进一步确定小麦fhb造成的严重程度,从402张图像中统计出了总穗、健康穗和患病穗的数量,然后计算了病穗率(x),采用决定系数(coefficient of determination,r2)和均方根误差(root mean squared error,rmse)来评估检测计数的准确性,根据病穗率的范围区间来确定fhb造成损伤的严重程度,病穗率和严重程度的确定均按小麦赤霉病测报技术规范来确定。此外,r2和以及病穗率的计算如公式:
[0030]
[0031]
其中i表示小麦图像的序列号yi表示图像i中小麦穗的真实数量,是图像i中预测的小麦穗的数量,是图像i的平均数量。n是图像的总数量。x表示病穗率,d表示患病穗数,t表示麦穗总数。
[0032]
小麦fhb的发病率主要由稳定期的病穗率决定,将发病率分为5个等级,即轻发生(1级)、偏轻发生(2级)、中等发生(3级)、偏重发生(4级)和大发生(5级),各级分级指标如下表:
[0033][0034]
本发明提供了一种在自然环境中快速检测小麦赤霉病穗及严重度的方法。具备以下有益效果:
[0035]
可实现自然环境中小麦fhb的快速、实时、准确检测,首先,采用轻量级主干mobilenetv3替代原有的yolov5s的主干网络,并将sppf模块嵌入主干网,增强模型感受野,以提高模型性能;使用c3ghost模块替换原来的c3模块,进一步减轻模型复杂度和参数量,降低对硬件设备的要求,可方便快捷地移植到移动设备上,改进模型实现了97.15%的map和80的fps,可以满足实时检测的要求,此外,改进模型的参数仅为3.64m,flops为4.77g,为了进一步确定小麦fhb的损失评估,本研究进一步统计出健康穗、患病穗、总穗,并将患病穗与总穗的比例作为病穗率,按照病穗率的范围确定小麦fhb严重度,病穗率的决定系数(r2)达0.9802,实现了较好的统计效果,结果表明,本文提出的改进型yolov5s满足移动设备的实时、高效、准确要求,能够在一系列自然环境中方便、快速地检测小麦fhb并确定严重度。
附图说明
[0036]
图1为本发明yolov5s模型的原始结构示意图;
[0037]
图2为本发明se模块示意图;
[0038]
图3为本发明c3ghost模块和内部结构示意图;
[0039]
图4为本发明改进的yolov5s模型的结构示意图;
[0040]
图5为本发明模型不同参数组合的结果对比示意图;
[0041]
图6为本发明模型训练的最优参数设置示意图;
[0042]
图7为本发明改进前后yolov5s的性能指标示意图;
[0043]
图8为本发明消融实验结果比较示意图;
[0044]
图9为本发明改进后的yolov5s的各指标和置信度的关系;
[0045]
图10为本发明不同模型的性能比较示意图;
[0046]
图11为本发明不同模型的识别效果对比示意图;
[0047]
图12为本发明小麦穗数统计的散点图;(a)健康麦穗数散点图;(b)
[0048]
患病麦穗散点图;(c)总麦穗散点图;(d)病穗率散点图。
具体实施方式
[0049]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完
整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0050]
请参阅图1-12,本发明实施例提供一种技术方案:一种在自然环境中快速检测小麦赤霉病穗及严重度的方法,所述步骤包括如下:
[0051]
s1:使用改进的yolov5s网络检测田间小麦穗,以检测病穗和健康穗;
[0052]
s2:将本研究提出的改进的yolov5s与yolov3-tiny、yolov4、ssd、faster r-cnn和yolov7模型进行了对比,验证了模型的有效性和优越性。
[0053]
所述步骤s2中模型为yolov5s模型,所述yolov5s是yolov4的改进版本,所述yolov5s模型是一个经典的单阶段结构(zang et al.,2022),它包括以下三部分:特征提取主干网络,特征融合颈部网络和检测头(t.jiang,li,yang,&wang,2022)yolov5s算法的检测过程包括以下三个主要步骤:
[0054]
(1)特征提取:将输入图像的尺寸调整为640
×
640,并将调整后的图像输入主干网络,主干网络集成了卷积(convolution,conv),c3,快速空间金字塔池化(fast spatial pyramid pooling mudule,sppf)等多种特征提取模块;
[0055]
(2)特征融合:主干网络生成的特征图传输到颈部网络,颈部网络采用panet结构进行多尺度特征融合,充分整合特征图提供的不同层和尺度的信息;
[0056]
(3)检测头:在颈部网络中融合特征后,该层的输出被输送到用于检测不同尺度的目标的三个检测头,这些检测头可分别检测小型、中型和大型目标。
[0057]
准确性和实时性是进行模型评估的关键,yolov5s是实时检测任务中较常用的目标检测模型之一,该模型在保证检测精度的前提下实现更快的检测速度和更小的模型尺寸,因此,本研究改进了yolov5s模型,以实现对小麦fhb中病穗的更轻量化的快速准确检测。
[0058]
所述步骤s1中包括mobilenetv3主干网络,采用轻量级网络mobilenetv3替换了yolov5s的原始主干网络,将sppf模块整合到主干网络中,以增强感受野和特征表达能力,从而提高检测精度,此外,我们将颈部的c3模块替换为c3ghost模块,以进一步减小模型尺寸,所述mobilenet3遵循mobilenet1的深度可分离卷积和mobilenet2的线性瓶颈和倒残差结构,并通过网络架构搜索(neural architecture search,nas)获取参数,它使用netadapt算法来获得卷积内核和通道的最佳数量,此外,该模型在优化过程中引入了h-swish函数和挤压和激励(squeeze-and-excitation,se)模块,大大提高了模型的速度和性能;
[0059]
h-swish是swish非线性的最新修改版本,与原始swish函数相比,其计算速度更快,对量化更友好计算公式如下:
[0060][0061]
所述se是一种注意力机制,通过自适应地调整特征图中每个通道的权重来提高模型的表达能力,se架构包括两个主要模块:挤压模块和激励模块。挤压模块通过全局平均池化操作将特征图的空间维度降为1x1,得到每个通道的全局特征描述。激励模块利用全连接层来学习每个通道的重要性权重,然后将这些权重应用于原始特征图,生成加权特征图,随
后转发到下一层进行处理;
[0062]
通过将注意力se模块插入到神经网络的不同层中,可以使网络更加关注重要的特征,减少对不重要特征的依赖,从而提高模型的性能和泛化能力。
[0063]
所述c3ghost是通过用ghost bottleneck替换原始的c3中的bottleneck来减少模型参数的引入的,ghost bottleneck包括ghostconv和深度卷积(depthwise convolution,dwconv),可以降低一般卷积层的计算复杂度和参数量,同时保持相似的识别性能(k.han et al.,2020;shang et al.,2023);
[0064]
所述步骤s2中还包括对模型的评估,利用多个指标来综合评估模型的性能,包括精度(precision,p)、召回率(recall,r)、f1得分、全类平均精度(mean average precision,map)、每秒帧数(frames per second,fps)、参数量(parameters)和每秒浮点运算次数(flops),p反映模型对正样本进行分类的能力,r评估模型找到正样本的能力,f1分数是p和r的调和平均值,map表示所有类别的平均精度的平均值,fps用于评估模型的检测速度,此外,parameters用于测量模型的大小,flops用于评估模型的计算复杂度,p、r、f1和map的计算方法如下:
[0065][0066][0067][0068][0069][0070]
其中tp表示正确检测到的正样本数,而fp表示错误检测到的正样本数,同样,tn表示正确检测到的负样本的数量,而fn表示错误检测到的负样本数,此外,n表示本研究中分析的数据类别的数量。
[0071]
所述步骤s1中还包括数据集的准备,为了满足对象检测的训练要求,使用labelme获得了每个图像对应的标签文件,在每张图像中手动将小麦穗标记为两类:fhb和healthy,共生成402个标记文件,共标注16,884个小麦穗,平均每个图像包含42个小麦穗,随后对图像进行了离线增强和在线增强,操作分别为:离线增强使用组合增强来模拟自然环境中样品的复杂性,组合增强通过翻转(水平和垂直)、亮度变换、锐化、对比度变换、模糊(高斯模糊、平均模糊、中值模糊之一)、拉伸和失真,在图像上进行不重复的组合操作处理,将组合数量限制为至多四个;在线增强选择马赛克增强和混合增强等方式,以提高模型的鲁棒性,在线增强功能包括色彩空间变换、随机水平翻转、图像缩放、图像平移、马赛克增强和mixup增强。
[0072]
将增强的小麦图像以8:2的比例分为训练集和测试集,随后,训练集进一步划分为训练集和验证集,比例为9:1,数据集包括1736张训练图像和193张验证图像以及483张测试图像,利用训练集训练模型,利用验证集来评估模型的泛化性,利用测试集来评估模型的准确性和鲁棒性,本步骤确保有足够的图像可用于训练、调整和测试模型。
[0073]
利用pytorch 1.10.0深度学习框架构建和改进模型,并在ubuntu20.04下对模型进行训练和测试,计算机的cpu是amd epyc 7642 48核处理器,2.3ghz,具有80g内存,gpu是nvidia geforce rtx 3090,具有24g视频内存,为了加快网络训练速度,我们使用gpu进行加速,cuda版本11.3和cudnn版本8.2.1,在训练过程中采用sgd优化算法,将sgd动量参数统一设置为0.937,初始学习率设置为0.01,权重衰减参数设置为5e-4,采用图像加权策略改善样本数量的不平衡问题,使用余弦退火算法更新学习率,将输入图像的尺寸调整为640
×
640像素,bacth size大小设置为32,以满足每个模型的训练需求,训练批次(epoch)总数设置为500。
[0074]
为了加速模型的训练和寻找最优参数设置,本研究重点进行了优化器的选择、图像加权策略和学习率的优化,选择的优化器是随机梯度下降(stochastic gradient descent,sgd)和自适应矩估计(adaptive moment estimation,adam),图像加权策略可以改善健康样本和患病样本之间数据量的不平衡。学习率也是除优化器和图像加权策略之外的重要参数,选择合适的学习率可以使模型在训练过程中受益,例如加快模型收敛速度和降低模型在最小值附近振荡的概率,因此,本研究也探讨了一般学习率和余弦退火学习率在模型性能上的差异。
[0075]
图5显示了模型在不同参数组合设置下的性能,从图5可以看出,带有sgd优化器的yolov5s的结果优于adam优化器,此外,当启用图像加权策略时,结果略有改善,表明图像加权策略可以解决部分样本不平衡的问题,开启余弦退火学习率后,模型性能进一步提高(map=96.49%),余弦退火学习率允许学习率进行余弦函数的周期性变化,从而提高模型的准确性,结果表明,参数的设置对模型至关重要,选择合适的参数可以在一定程度上改善模型的性能。
[0076]
我们为模型的后续训练和验证选择性能最佳的参数设置。在训练过程中采用sgd优化算法,将sgd动量参数统一设置为0.937。初始学习率设置为0.01,权重衰减参数设置为5e-4。采用图像加权策略改善样本的不平衡问题,余弦退火算法更新学习率。将输入图像的尺寸统一调整为640
×
640像素,bacth size设置为32,以满足每个模型的训练需求。训练周期总数设置为500。模型训练的参数设置如图6所示。
[0077]
图7展示了在训练和验证过程中,改进的yolov5s和原始yolov5s的map的变化过程。我们观察到,在最初的160个epoch,两种模型的map都急剧增加。然而,在大约160个epoch之后,改进的yolov5s模型的map与原始模型相比逐渐增加了约2个百分点。到500个epoch结束时,所有性能指标开始稳定,表明模型已经收敛。我们的结果表明,虽然我们模型的收敛速度略慢于原始yolov5s,但我们改进的模型在最终性能方面优于原始yolov5s。
[0078]
本研究通过消融实验(图8)以探索mobilenetv3和c3ghost模块对模型的影响,集成mobilenetv3和c3ghost模块足以保证准确性和速度(map=97.15%,fps=80),此外,与仅添加mobilenetv3(fps=71.93)相比,添加c3ghost模块可以进一步减小模型大小并加快检测速度(fps=80),值得注意的是,与原来的yolov5相比,所提出的模型的fps提高了10.5,参数数量减少了49.72%,flops减少了71.32%,确保所提出的模型具有最小的模型尺寸和最高的检测速度,不会影响检测的准确性。
[0079]
本研究也评估了模型的置信度、精确率、召回率和f1之间的关系图,同时绘制了pr曲线以可视化定性结果(图9),使结果更加直观,这些曲线揭示了模型的精确率、召回率和
f1在不同置信度下的变化,从而能更好地了解模型的性能和有效性,从置信度和精确率曲线可以看出,当置信度为0.05或更高时,模型精度在80%以上并稳步提高。此外,当置信水平低于0.8时,召回率仍然很高,但当置信水平高于0.8时,召回率开始逐渐下降,f1是精确率和召回率的综合评估指标,随着置信阈值从低到高的增加,它也发生了相应的变化,在0.05至0.9范围内,该模型在不同置信度下均表现出较高的f1得分,表明改进的yolov5s在更宽的置信区间内具有更高的准确性和稳定性,结合pr曲线分析,可以看出我们提出的改进yolov5s表现出优越的泛化能力和鲁棒性,并且可以在较低的置信阈值下实现较高的检测精度。
[0080]
为了验证改进的yolov5s对小麦fhb检测的有效性,本研究比较了其他5种目标检测算法,包括yolov3-tiny,yolov4,ssd,faster r-cnn和yolov7。每个模型都在相同的条件下进行训练、验证和测试。然后,使用测试集评估6种检测算法的性能。基于图10中给出的结果,我们提出的改进型yolov5s和yolov7实现了最佳的检测性能,map超过96.9%,然而,观察到yolov7的flops和参数量明显高于我们提出的方法,尽管yolov7可以达到相当的精度,但其较大的模型复杂性和参数阻碍了在移动设备上有效便捷的可移植性,yolov3-tiny的fps最高,表明实时性能更好,但map相对较差,仅为88.22%,与yolov4、fasterr-cnn和ssd模型相比,所提出的方法在map、fps和模型参数等方面均表现出优异的性能,上述结果表明,我们提出的改进的yolov5s可以有效地应用于小麦fhb的快速检测,该算法的模型尺寸更小,检测速度更快,更有利于模型在移动设备上的部署。
[0081]
从图11可以观察到,各模型都存在一定程度的漏检、重复和错误检测的问题。具体而言,yolov3-tiny表现出对小麦穗的严重重复检测,而yolov4通过解决小麦穗的重复检测和漏检问题,展示了其检测小物体的改进能力。另一方面,ssd存在明显的漏检和错误检测问题,重复检测的发生较少。faster r-cnn存在明显的漏检问题,从而表明其在多目标情况下的性能较差。改进的yolov5s和yolov7显示出更少的漏检和错误检测。与其他5种模型相比,改进后的yolov5s在检测小物体方面表现出色,在解决重复检测问题的同时,在检测小物体方面有了显着改进。
[0082]
通过使用r2和rmse来评估预测效果,并使用散点图进行健康穗,患病穗和总穗的可视化,从图12中可以看出本研究收集的图像数据中健康小麦穗较少,患病小麦穗较多。健康小麦穗的r2为0.9508,患病小麦穗的r2为0.9899,总穗的r2为0.9841,rmse均较小。结果表明,本研究提出的改进yolov5s具有良好的识别和检测效果,错误检测和漏检率最小。这进一步确保了使用该模型获得的病穗率的准确性。此外,病穗率集中在0.6-1.0范围内,说明研究区fhb感染较重,与实际情况一致。本研究结果进一步为小麦fhb的损失评估提供了可靠的依据和参考。
[0083]
以上显示和描述了本发明的基本原理和主要特征和本发明的优点,对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
[0084]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包
含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!