异常检测方法和装置、模型训练方法和装置、存储介质与流程-j9九游会真人
1.本公开涉及信息处理领域,特别涉及一种异常检测方法和装置、模型训练方法和装置、存储介质。
背景技术:
2.iptv(internet protocol television,网络电视)业务播放用户数如果出现突发下降趋势,很可能是网络设备出现大规模故障导致,因此在线播放用户数指标的实时检测对于网络运维而言是十分重要的。
3.在目前的iptv智能化运维系统中设有聚类模型和多个检测模型。首先利用聚类模型对位于各个地市的设备感知的样本进行聚类,并将同一类别的样本输入与该类别相关联的检测模型进行检测。
技术实现要素:
4.发明人注意到,在相关技术中,需要对聚类模型和检测模型进行训练。由于聚类模型的训练过程和检测模型的训练过程之间没有关联性,因此会出现误差累积的情况。即,聚类的误差会影响到各检测模型的检测效果。
5.据此,本公开提供一种异常检测方法,通过构造混合专家模型,有效避免了误差累积的情况发生,同时还有效提高了训练和预测速度。
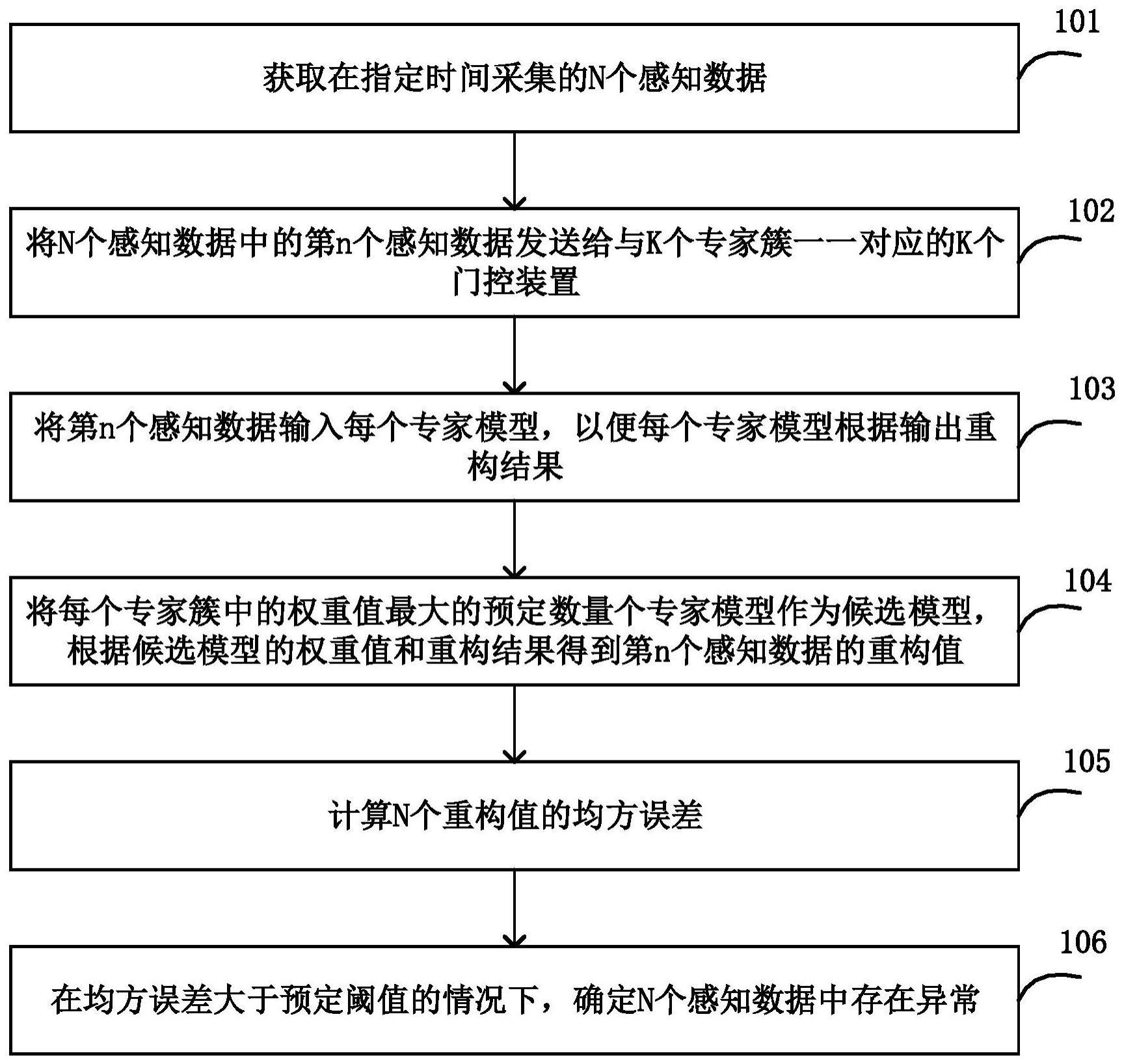
6.在本公开的第一方面,提供一种异常检测方法,由异常检测装置执行,所述方法包括:获取在指定时间采集的n个感知数据;将所述n个感知数据中的第n个感知数据xn发送给与k个专家簇一一对应的k个门控装置,其中每个专家簇包括m个专家模型,以便每个门控装置根据所述xn为对应专家簇中的每个专家模型生成权重,1≤n≤n,k、m、n为大于1的自然数;将所述xn输入所述每个专家模型,以便所述每个专家模型根据所述xn输出重构结果;将所述每个专家簇中的权重值最大的预定数量个专家模型作为候选模型,并根据所述候选模型的权重值和重构结果得到所述xn的重构值;计算n个重构值的均方误差;在所述均方误差大于预定阈值的情况下,确定所述n个感知数据中存在异常情况。
7.在一些实施例中,第i个专家簇中的第j个专家模型的权重g
ij
(xn)由所述xn、所述第i个专家簇中的所述第j个专家模型的权重参数w
ij
和随机参数noise
ij
确定,其中1≤i≤k,1≤j≤m。
8.在一些实施例中,所述权重g
ij
(xn)为:g
ij
(xn)=w
ij
·
xn noise
ij
。
9.在一些实施例中,所述随机参数noise
ij
由所述xn、所述第i个专家簇中的所述第j个专家模型的噪声参数和满足预设条件的随机数确定。
10.在一些实施例中,所述随机参数noise
ij
为
[0011][0012]
其中,rand为用于生成满足所述预设条件的随机数的随机数生成函数,softplus
[0026]
其中,γ为权重,cv为变异系数函数,w(x)为所述全部候选模型的权重值之和。
[0027]
在本公开的第五方面,提供一种模型训练装置,包括:第一训练处理模块,被配置为将n个样本数据中的第n个样本数据xn发送给与k个专家簇一一对应的k个门控装置,其中每个专家簇包括m个专家模型,以便每个门控装置根据所述xn为对应专家簇中的每个专家模型生成权重,1≤n≤n,k、m、n为大于1的自然数,将所述xn输入所述每个专家模型,以便所述每个专家模型根据所述xn输出重构结果,将所述每个专家簇中的权重值最大的预定数量个专家模型作为候选模型,并根据所述候选模型的权重值和重构结果得到所述xn的重构值;第二训练处理模块,被配置为根据所述n个样本数据和得到的n个重构值确定损失函数;第三训练处理模块,被配置为根据损失函数对所述专家模型进行训练。
[0028]
在本公开的第六方面,提供一种模型训练装置,包括:存储器;处理器,耦合到存储器,处理器被配置为基于存储器存储的指令执行实现如上述任一实施例所述的方法。
[0029]
根据本公开实施例的第七方面,提供一种计算机可读存储介质,其中,计算机可读存储介质存储有计算机指令,指令被处理器执行时实现如上述任一实施例所述的方法。
[0030]
通过以下参照附图对本公开的示例性实施例的详细描述,本公开的其它特征及其优点将会变得清楚。
附图说明
[0031]
为了更清楚地说明本公开实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0032]
图1为本公开一个实施例的异常检测方法的流程示意图;
[0033]
图2为本公开一个实施例的混合专家模型的结构示意图;
[0034]
图3为本公开一个实施例的异常检测装置的结构示意图;
[0035]
图4为本公开另一个实施例的异常检测装置的结构示意图;
[0036]
图5为本公开一个实施例的模型训练方法的流程示意图;
[0037]
图6为本公开一个实施例的模型训练装置的结构示意图;
[0038]
图7为本公开另一个实施例的模型训练装置的结构示意图。
具体实施方式
[0039]
下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本公开一部分实施例,而不是全部的实施例。以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本公开及其应用或使用的任何限制。基于本公开中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。
[0040]
除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本公开的范围。
[0041]
同时,应当明白,为了便于描述,附图中所示出的各个部分的尺寸并不是按照实际的比例关系绘制的。
[0042]
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为授权说明书的一部分。
[0043]
在这里示出和讨论的所有示例中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它示例可以具有不同的值。
[0044]
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。
[0045]
图1为本公开一个实施例的异常检测方法的流程示意图。在一些实施例中,下列的异常检测方法由异常检测装置执行。
[0046]
在步骤101,获取在指定时间采集的n个感知数据,n为大于1的自然数。
[0047]
这里需要说明的是,指定时间可以是一个时间点,也可以是一个时间区间。
[0048]
在一些实施例中,感知数据为指定业务在线播放用户数。
[0049]
例如,指定业务为iptv业务。
[0050]
在一些实施例中,对采集的感知数据进行离群值检测,对检测出的离群值进行平滑处理,例如采用离群值的前后值的均值进行替代。此外,针对丢失的数据片段,利用线性插补的方法进行填充。
[0051]
在步骤102,将n个感知数据中的第n个感知数据xn发送给与k个专家簇一一对应的k个门控装置,其中每个专家簇包括m个专家模型,以便每个门控装置根据xn为对应专家簇中的每个专家模型生成权重,1≤n≤n,k、m为大于1的自然数。
[0052]
在一些实施例中,专家模型为变分自编码器(variational autoencoder,简称:vae)。
[0053]
如图2所示,混合专家模型中包括k个专家簇c1-ck,专家簇c1中设有一个门控装置g1和m个专家模型em
11-em
1m
,以此类推,专家簇ck中设有一个门控装置gk和m个专家模型em
k1-em
km
。
[0054]
在一些实施例中,第i个专家簇中的第j个专家模型的权重g
ij
(xn)由xn、第i个专家簇中的第j个专家模型的权重参数w
ij
和随机参数noise
ij
确定,其中1≤i≤k,1≤j≤m。
[0055]
例如,权重g
ij
(xn)如公式(1)所示。
[0056]gij
(xn)=w
ij
·
xn noise
ij
ꢀꢀꢀꢀ
(1)
[0057]
在一些实施例中,随机参数noise
ij
由xn、第i个专家簇中的第j个专家模型的噪声参数和满足预设条件的随机数确定。
[0058]
例如,随机参数noise
ij
如公式(2)所示。
[0059][0060]
其中,rand为用于生成满足预设条件的随机数的随机数生成函数,softplus为激活函数,和为预设的噪声参数。
[0061]
例如,rand生成的随机数呈标准正态分布,即rand生成的随机数的均值为0,方差为1。
[0062]
需要说明的是,通过在权重中增加随机参数,以便使得各专家模型间的权重更加均衡。
[0063]
在步骤103,将xn输入每个专家模型,以便每个专家模型根据xn输出重构结果。
[0064]
在步骤104,将每个专家簇中的权重值最大的预定数量个专家模型作为候选模型,并根据候选模型的权重值和重构结果得到xn的重构值。
[0065]
在一些实施例中,根据每个专家簇中的候选模型的权重值和重构结果确定每个专家簇的重构分量,并根据每个专家簇的重构分量确定xn的重构值。
[0066]
例如,xn的重构值yn如公式(3)所示。
[0067][0068]
其中,softplus为激活函数,k
′
为预定数量,topki(g
ij
(xn),k
′
)为用于选择出第i个专家簇中的候选模型的选择函数,e
ij
(xn)为第i个专家簇中的第j个专家模型输出的重构结果。
[0069]
需要说明的是,topki(g
ij
(xn),k
′
)的处理方式为:
[0070]
1)将第i个专家簇中的m个专家模型按照权重从大到小的顺序进行排列,以得到专家模型队列。也就是说,专家模型队列中的第1个专家模型的权重v1最大,第m个专家模型的权重vm最小。
[0071]
2)将专家模型队列中的前k
′
个专家模型的权重维持不变,而将专家模型队列中的其它专家模型的权重调整为-∞,即屏蔽权重为-∞的专家模型参与后续处理。上述处理如公式(4)所示。
[0072][0073]
需要说明的是,由于topk算法是本领域技术人员所了解的,因此这里不展开描述。
[0074]
在一些实施例中,k
′
为1。在这种情况下,每个专家簇中仅使用权重最大的专家模型进行相应处理。
[0075]
在步骤105,计算n个重构值的均方误差。
[0076]
在步骤106,在均方误差大于预定阈值的情况下,确定n个感知数据中存在异常情况。
[0077]
在本公开上述实施例提供的异常检测方法中,通过构造混合专家模型,不再使用先聚类后检测的传统方式,从而有效避免了误差累积的情况发生,同时还有效提高了训练和预测速度。
[0078]
图3为本公开一个实施例的异常检测装置的结构示意图。如图3所示,异常检测装置包括第一检测处理模块31、第二检测处理模块32和第三检测处理模块33。
[0079]
第一检测处理模型31被配置为获取在指定时间采集的n个感知数据。
[0080]
这里需要说明的是,指定时间可以是一个时间点,也可以是一个时间区间。
[0081]
在一些实施例中,感知数据为指定业务在线播放用户数。
[0082]
例如,指定业务为iptv业务。
[0083]
在一些实施例中,第一检测处理模型31对采集的感知数据进行离群值检测,对检测出的离群值进行平滑处理,例如采用离群值的前后值的均值进行替代。此外,针对丢失的数据片段,利用线性插补的方法进行填充。
[0084]
第二检测处理模型32被配置为将n个感知数据中的第n个感知数据xn发送给与k个专家簇一一对应的k个门控装置,其中每个专家簇包括m个专家模型,以便每个门控装置根
据xn为对应专家簇中的每个专家模型生成权重,1≤n≤n,k、m、n为大于1的自然数,将xn输入每个专家模型,以便每个专家模型根据xn输出重构结果,将每个专家簇中的权重值最大的预定数量个专家模型作为候选模型,并根据候选模型的权重值和重构结果得到xn的重构值。
[0085]
在一些实施例中,专家模型为变分自编码器。
[0086]
如图2所示,混合专家模型中包括k个专家簇c1-ck,专家簇c1中设有一个门控装置g1和m个专家模型em
11-em
1m
,以此类推,专家簇ck中设有一个门控装置gk和m个专家模型em
k1-em
km
。
[0087]
在一些实施例中,第i个专家簇中的第j个专家模型的权重g
ij
(xn)由xn、第i个专家簇中的第j个专家模型的权重参数w
ij
和随机参数noise
ij
确定,其中1≤i≤k,1≤j≤m。
[0088]
例如,权重g
ij
(xn)如公式(1)所示。
[0089]
在一些实施例中,随机参数noise
ij
由xn、第i个专家簇中的第j个专家模型的噪声参数和满足预设条件的随机数确定。
[0090]
例如,随机参数noise
ij
如公式(2)所示。
[0091]
需要说明的是,通过在权重中增加随机参数,以便使得各专家模型间的权重更加均衡。
[0092]
在一些实施例中,第二检测处理模型32根据每个专家簇中的候选模型的权重值和重构结果确定每个专家簇的重构分量,并根据每个专家簇的重构分量确定xn的重构值。
[0093]
例如,xn的重构值yn如公式(3)所示。
[0094]
第三检测处理模型33被配置为计算n个重构值的均方误差,在均方误差大于预定阈值的情况下,确定n个感知数据中存在异常情况。
[0095]
图4为本公开另一个实施例的异常检测装置的结构示意图。如图4所示,异常检测装置包括存储器41和处理器42。
[0096]
存储器41用于存储指令,处理器42耦合到存储器41,处理器42被配置为基于存储器存储的指令执行实现如图1中任一实施例涉及的方法。
[0097]
如图4所示,该异常检测装置还包括通信接口43,用于与其它设备进行信息交互。同时,该异常检测装置还包括总线44,处理器42、通信接口43、以及存储器41通过总线44完成相互间的通信。
[0098]
存储器41可以包含高速ram存储器,也可还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。存储器41也可以是存储器阵列。存储器41还可能被分块,并且块可按一定的规则组合成虚拟卷。
[0099]
此外,处理器42可以是一个中央处理器cpu,或者可以是专用集成电路asic,或是被配置成实施本公开实施例的一个或多个集成电路。
[0100]
本公开同时还涉及一种计算机可读存储介质,其中计算机可读存储介质存储有计算机指令,指令被处理器执行时实现如图1中任一实施例涉及的方法。
[0101]
图5为本公开一个实施例的模型训练方法的流程示意图。在一些实施例中,下列的模型训练方法由模型训练装置执行。
[0102]
在步骤501,将n个样本数据中的第n个样本数据xn发送给与k个专家簇一一对应的k个门控装置,其中每个专家簇包括m个专家模型,以便每个门控装置根据xn为对应专家簇
中的每个专家模型生成权重,1≤n≤n,k、m、n为大于1的自然数。
[0103]
在一些实施例中,样本数据为指定业务在线播放用户数。
[0104]
例如,指定业务为iptv业务。
[0105]
在一些实施例中,专家模型为变分自编码器。
[0106]
如图2所示,混合专家模型中包括k个专家簇c1-ck,专家簇c1中设有一个门控装置g1和m个专家模型em
11-em
1m
,以此类推,专家簇ck中设有一个门控装置gk和m个专家模型em
k1-em
km
。
[0107]
在一些实施例中,第i个专家簇中的第j个专家模型的权重g
ij
(xn)由xn、第i个专家簇中的第j个专家模型的权重参数w
ij
和随机参数noise
ij
确定,其中1≤i≤k,1≤j≤m。
[0108]
例如,权重g
ij
(xn)如公式(1)所示。
[0109]
在一些实施例中,随机参数noise
ij
由xn、第i个专家簇中的第j个专家模型的噪声参数和满足预设条件的随机数确定。
[0110]
例如,随机参数noise
ij
如公式(2)所示。
[0111]
需要说明的是,通过在权重中增加随机参数,以便使得各专家模型间的权重更加均衡。
[0112]
在步骤502,将xn输入每个专家模型,以便每个专家模型根据xn输出重构结果。
[0113]
在步骤503,将每个专家簇中的权重值最大的预定数量个专家模型作为候选模型,并根据候选模型的权重值和重构结果得到xn的重构值。
[0114]
在一些实施例中,根据每个专家簇中的候选模型的权重值和重构结果确定每个专家簇的重构分量,并根据每个专家簇的重构分量确定xn的重构值。
[0115]
例如,xn的重构值yn如公式(3)所示。
[0116]
在步骤504,根据n个样本数据和得到的n个重构值确定损失函数。
[0117]
在一些实施例中,损失函数包括正则项l1、重构误差项l2和平衡项l3,其中正则项l1由n个样本数据的均值和方差确定,重构误差项l2由n个重构值的均方误差确定,平衡项l3由全部候选模型的权重值确定。
[0118]
在一些实施例中,损失函数l如公式(5)所示。
[0119]
l=l1 l2 l3ꢀꢀ
(5)
[0120]
这里需要说明的是,正则项l1如公式(6)所示,重构误差项l2如公式(7)所示,平衡项l3如公式(8)所示。
[0121][0122]
其中,σ为同一批(batch)中样本的方差,μ为同一批中样本的均值。
[0123][0124]
其中,y为样本值,为对应的重构值。
[0125]
需要说明的是,由于正则项l1和重构误差项l2是本领域技术人员所了解的,因此这里不展开描述。
[0126]
l3=γ
·
cv(w(x))2ꢀꢀ
(8)
[0127]
其中,γ为权重,cv为变异系数(coefficient of variation)函数,w(x)为全部候
选模型的权重值之和。
[0128]
这里需要说明的是,通过设置平衡项l3,能够让尽可能多的专家模型参与检测处理。
[0129]
在步骤505,根据损失函数对专家模型进行训练。
[0130]
图6为本公开一个实施例的模型训练装置的结构示意图。如图6所示,模型训练装置包括第一训练处理模块61、第二训练处理模块62和第三训练处理模块63。
[0131]
第一训练处理模块61被配置为将n个样本数据中的第n个样本数据xn发送给与k个专家簇一一对应的k个门控装置,其中每个专家簇包括m个专家模型,以便每个门控装置根据xn为对应专家簇中的每个专家模型生成权重,1≤n≤n,k、m、n为大于1的自然数,将xn输入每个专家模型,以便每个专家模型根据xn输出重构结果,将每个专家簇中的权重值最大的预定数量个专家模型作为候选模型,并根据候选模型的权重值和重构结果得到xn的重构值。
[0132]
在一些实施例中,样本数据为指定业务在线播放用户数。
[0133]
例如,指定业务为iptv业务。
[0134]
在一些实施例中,专家模型为变分自编码器。
[0135]
如图2所示,混合专家模型中包括k个专家簇c1-ck,专家簇c1中设有一个门控装置g1和m个专家模型em
11-em
1m
,以此类推,专家簇ck中设有一个门控装置gk和m个专家模型em
k1-em
km
。
[0136]
在一些实施例中,第i个专家簇中的第j个专家模型的权重g
ij
(xn)由xn、第i个专家簇中的第j个专家模型的权重参数w
ij
和随机参数noise
ij
确定,其中1≤i≤k,1≤j≤m。
[0137]
例如,权重g
ij
(xn)如公式(1)所示。
[0138]
在一些实施例中,随机参数noise
ij
由xn、第i个专家簇中的第j个专家模型的噪声参数和满足预设条件的随机数确定。
[0139]
例如,随机参数noise
ij
如公式(2)所示。
[0140]
需要说明的是,通过在权重中增加随机参数,以便使得各专家模型间的权重更加均衡。
[0141]
在一些实施例中,第一训练处理模块61根据每个专家簇中的候选模型的权重值和重构结果确定每个专家簇的重构分量,并根据每个专家簇的重构分量确定xn的重构值。
[0142]
例如,xn的重构值yn如公式(3)所示。
[0143]
第二训练处理模块62被配置为根据n个样本数据和得到的n个重构值确定损失函数。
[0144]
在一些实施例中,损失函数包括正则项l1、重构误差项l2和平衡项l3,其中正则项l1由n个样本数据的均值和方差确定,重构误差项l2由n个重构值的均方误差确定,平衡项l3由全部候选模型的权重值确定。
[0145]
在一些实施例中,损失函数l如公式(5)所示,正则项l1如公式(6)所示,重构误差项l2如公式(7)所示,平衡项l3如公式(8)所示。
[0146]
这里需要说明的是,通过设置平衡项l3,能够让尽可能多的专家模型参与检测处理。
[0147]
第三训练处理模块63被配置为根据损失函数对专家模型进行训练。
[0148]
图7为本公开另一个实施例的模型训练装置的结构示意图。如图7所示,模型训练装置包括存储器71、处理器72、通信接口73和总线74。图7和图4的不同之处在于,在图7所示实施例中,处理器72被配置为基于存储器存储的指令执行实现如图5中任一实施例涉及的方法。
[0149]
在一些实施例中,在上面所描述的功能单元可以实现为用于执行本公开所描述功能的通用处理器、可编程逻辑控制器(programmable logic controller,简称:plc)、数字信号处理器(digital signal processor,简称:dsp)、专用集成电路(application specific integrated circuit,简称:asic)、现场可编程门阵列(field-programmable gate array,简称:fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件或者其任意适当组合。
[0150]
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
[0151]
本公开的描述是为了示例和描述起见而给出的,而并不是无遗漏的或者将本公开限于所公开的形式。很多修改和变化对于本领域的普通技术人员而言是显然的。选择和描述实施例是为了更好说明本公开的原理和实际应用,并且使本领域的普通技术人员能够理解本公开从而设计适于特定用途的带有各种修改的各种实施例。
当前第1页1
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!