一种基于nna的fc层地址连续的输入数据处理方法与流程-j9九游会真人
一种基于nna的fc层地址连续的输入数据处理方法
技术领域
1.本发明涉及神经网路技术领域,特别涉及一种基于nna的fc层地址连续的输入数据处理方法。
背景技术:
2.神经网络技术的应用日益普及,使得芯片厂商为神经网络算法打造专用的芯片,尤其是推理端的芯片,也就是神经网络加速器(nna)。现有技术中,nna支持多通道卷积的快速运算。卷积神经网络主要由输入层、卷积层、池化层和全连接层组成,其中,全连接层(fc)实现逻辑:输入数据与权重对应相乘,得到一个数,存入输出空间。dma搬运数据的规则,数据搬运的源地址和目的地址需要64对齐,dma搬运数据量需要64字节对齐,只有这三个条件都满足时,才能确保dma数据的正确性。输入层算子采取的按行dma搬运数据,即以输入featuremap每行作为一个dma数据块,将卷积所需的输入featuremap数据搬运到目的存储空间。但是,由于输入层的输入featuremap数据未进行iline_size64字节对齐,地址连续存储,按行dma搬运数据,那么下一行首地址错误,导致计算结果错误。与地址非连续存储比较,两者差异主要在于数据在内存中排布方式不一致,在取数时需要考虑不同策略。
3.此外,现有技术中的常用术语如下:
4.1、nna:在cpu的simd的pipeline上的硬件加速器,操作由特殊的cpu/simd指令控制,在一个线程上运行,用以解决绝大部分的卷积乘加。
5.2、fc层(fully connected layer全连接层):将前面网络学到的特征映射到样本标记空间,主要起分类的作用。
6.3、feature_shape:输入数据的形状,抽象理解为多维度数据,从左到右依次是从高维到低维(ndhwc),n:一次处理featuremap数量,设置为1;d:输入通道拆分为32一组的个数;h:输入数据的高;w:输入数据的宽;c:32。
7.4、对齐:字节对齐:由于硬件限制,每一次处理的数据大小必须保证是64字节对齐。align64(x):align64(x)=(x 63)/64*64;行对齐:每一行数据需要保证64字节对齐,本发明无需考虑行对齐情况。
8.5、dma:全称direct memory access,即直接存储器访问,dma传输将数据从一个地址空间复制到另一个地址空间,提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。
9.6、mac:基于nna的卷积累乘和计算
10.7、inline_size:css属性影响一个元素的width和height,以改变一个元素的盒模型的水平或垂直大小。
技术实现要素:
11.为了解决上述问题,本技术的目的在于:本发明克服由运用dma搬运数据带来的输
入featuremap iline_size 64字节对齐,解决在全连接层数据非对齐的情况下,使用dma正确的搬运数据。将权重、输入数据分组计算,减少数据搬运之间的等待时间。
12.具体地,本发明提供一种基于nna的fc层地址连续的输入数据处理方法,所述方法中地址连续无需考虑行对齐,包括以下步骤:
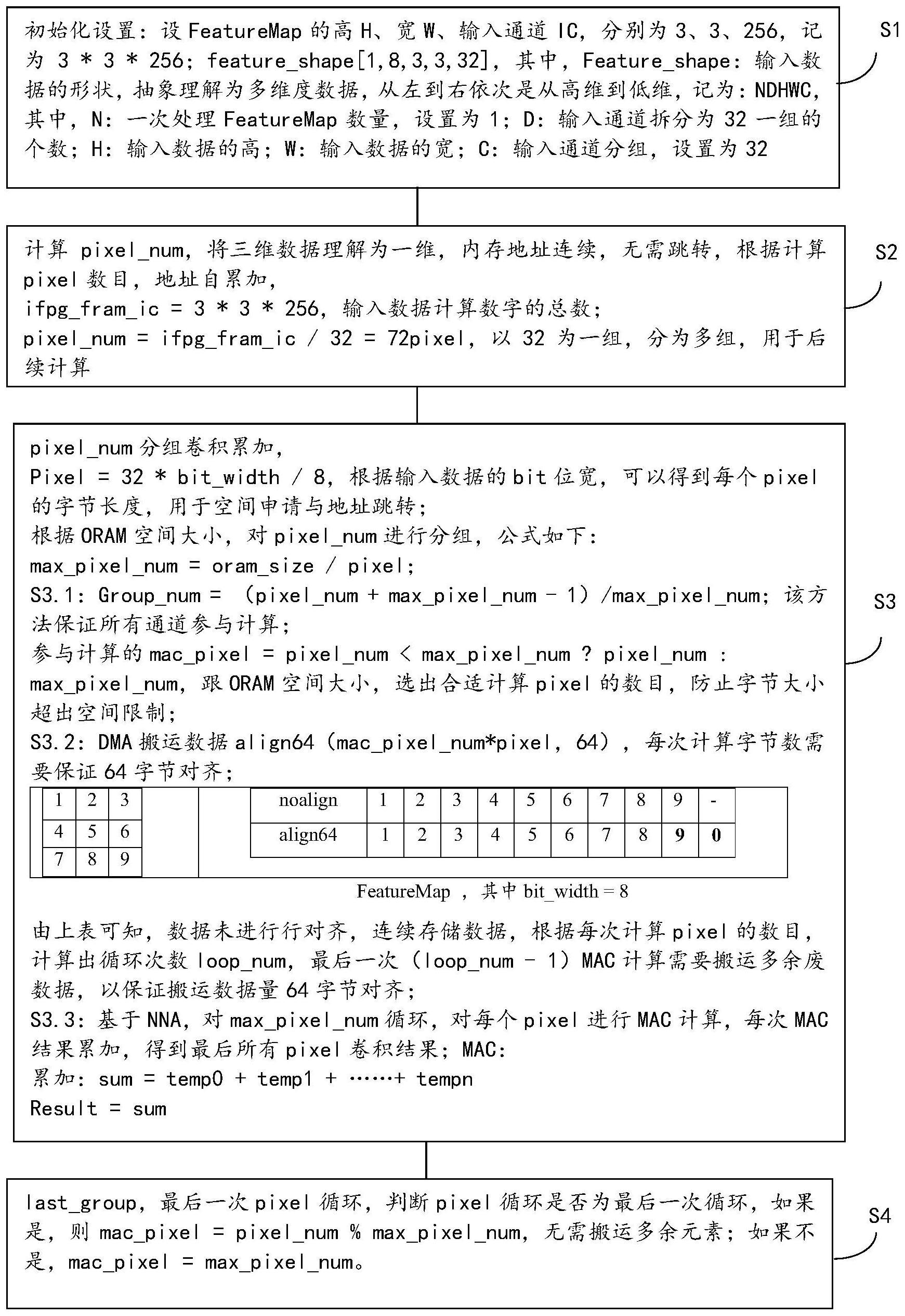
13.s1,初始化设置:
14.设featuremap的高h、宽w、输入通道ic,分别为3、3、256,记为3*3*256;feature_shape[1,8,3,3,32],其中,feature_shape:输入数据的形状,抽象理解为多维度数据,从左到右依次是从高维到低维,记为:ndhwc,其中,
[0015]
n:一次处理featuremap数量,设置为1;
[0016]
d:输入通道拆分为32一组的个数;
[0017]
h:输入数据的高;
[0018]
w:输入数据的宽;
[0019]
c:输入通道分组,设置为32;
[0020]
s2:计算pixel_num,将三维数据理解为一维,内存地址连续,无需跳转,根据计算pixel数目,地址自累加,
[0021]
ifpg_fram_ic=3*3*256,输入数据计算数字的总数;
[0022]
pixel_num=ifpg_fram_ic/32=72pixel,以32为一组,分为多组,用于后续计算;
[0023]
s3:pixel_num分组卷积累加,
[0024]
pixel=32*bit_width/8,根据输入数据的bit位宽,可以得到每个pixel的字节长度,用于空间申请与地址跳转;
[0025]
根据oram空间大小,对pixel_num进行分组,公式如下:max_pixel_num=oram_size/pixel;
[0026]
s3.1:group_num=(pixel_num max_pixel_num-1)/max_pixel_num;该方法保证所有通道参与计算;
[0027]
参与计算的mac_pixel=pixel_num《max_pixel_num?pixel_num:max_pixel_num,跟oram空间大小,选出合适计算pixel的数目,防止字节大小超出空间限制;
[0028]
s3.2:dma搬运数据align64(mac_pixel_num*pixel,64),每次计算字节数需要保证64字节对齐;
[0029]
设宽、高二维,排列数据如下:
[0030]
123456789
[0031]
则
[0032]
noalign123456789-align641234567890
[0033]
featuremap,其中bit_width=8
[0034]
由上表可知,数据未进行行对齐,连续存储数据,根据每次计算pixel的数目,计算出循环次数loop_num,最后一次(loop_num-1)mac计算需要搬运多余废数据,以保证搬运数据量64字节对齐;
[0035]
s3.3:基于nna,即基于硬件计算卷积相乘累加和,对max_pixel_num循环,对每个pixel进行mac计算,每次mac结果累加,得到最后所有pixel卷积结果;
[0036]
mac:
[0037]
累加:sum=temp0 temp1
……
tempn
[0038]
result=sum;
[0039]
s4:last_group,最后一次pixel循环,
[0040]
判断pixel循环是否为最后一次循环,如果是,则mac_pixel=pixel_num%max_pixel_num,无需搬运多余元素;如果不是,mac_pixel=max_pixel_num。
[0041]
所述步骤s3.1中,当oram空间不足以放下所有数据,则输入数据分组搬运,每次搬运最大空间可装载数据,反之如果能够放下所有数据,将数据一次dma搬运到oram空间。
[0042]
所述步骤s4中无需搬运多余元素,例如一共3*3*256=2304个pixel,每次计算90个pixel,最后一次只需要计算54个pixel,
[0043]
noalign123456789-align641234567890
[0044]
其中上表中第二行最后两个位置内的数据搬运只需保证64字节对齐,以减少搬运数据量。
[0045]
由此,本技术的优势在于:通过简单的方法,在输入层地址连续前提下,地址连续无需考虑行对齐,解决未进行行对齐的基于nna卷积计算。
附图说明
[0046]
此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,并不构成对本发明的限定。
[0047]
图1是本技术涉及nna、oram和ddr的框架示意图。
[0048]
图2是本技术涉及featuremap的示意图。
[0049]
图3是本技术方法的流程示意图。
具体实施方式
[0050]
为了能够更清楚地理解本发明的技术内容及优点,现结合附图对本发明进行进一步的详细说明。
[0051]
由于nna有一些硬性条件限制,只支持多通道卷积,在实际应用中通用性不高。nna实际上支持的是普通无符号输入和普通无符号权重乘累加的快速计算,而多通道卷积是普通无符号输入和普通有符号权重乘累加的结果。实际使用时需要通过配置nna相关寄存器才可以快速得到正确的卷积结果。
[0052]
本发明主要通过dma搬运多余废数据来保证搬运数据64字节对齐,将搬运的数据存到oram空间,用于nna计算。
[0053]
fram:输入数据空间;wram:权重数据空间,如图1所示。
[0054]
将输入数据从oram中存储到fram,权重数据从oram中存储到wram,经过nna计算,得到卷积的结果。
[0055]
例:featuremap的h、w、ic分别为3*3*256;feature_shape[1,8,3,3,32]。如图2所示:数据的形状以三维排列,本发明可将三维数据理解为一维数据,直接用于后续计算。
[0056]
如图3所示:本方法进一步包括以下步骤:
[0057]
所述方法中地址连续无需考虑行对齐,包括以下步骤:
[0058]
s1,初始化设置:
[0059]
设featuremap的高h、宽w、输入通道ic,分别为3、3、256,记为3*3*256;feature_shape[1,8,3,3,32],其中,feature_shape:输入数据的形状,抽象理解为多维度数据,从左到右依次是从高维到低维,记为:ndhwc,其中,
[0060]
n:一次处理featuremap数量,设置为1;
[0061]
d:输入通道拆分为32一组的个数;
[0062]
h:输入数据的高;
[0063]
w:输入数据的宽;
[0064]
c:输入通道分组,设置为32;
[0065]
s2:计算pixel_num,将三维数据理解为一维,内存地址连续,无需跳转,根据计算pixel数目,地址自累加,
[0066]
ifpg_fram_ic=3*3*256,输入数据计算数字的总数;
[0067]
pixel_num=ifpg_fram_ic/32=72pixel,以32为一组,分为多组,用于后续计算;
[0068]
s3:pixel_num分组卷积累加,
[0069]
pixel=32*bit_width/8,根据输入数据的bit位宽,可以得到每个pixel的字节长度,用于空间申请与地址跳转;
[0070]
根据oram空间大小,对pixel_num进行分组,公式如下:max_pixel_num=oram_size/pixel;
[0071]
s3.1:group_num=(pixel_num max_pixel_num-1)/max_pixel_num;该方法保证所有通道参与计算;
[0072]
参与计算的mac_pixel=pixel_num《max_pixel_num?pixel_num:max_pixel_num,跟oram空间大小,选出合适计算pixel的数目,防止字节大小超出空间限制;
[0073]
s3.2:dma搬运数据align64(mac_pixel_num*pixel,64),每次计算字节数需要保证64字节对齐;
[0074]
以宽、高二维为例,排列数据:
[0075]
123456789
[0076]
则
[0077]
noalign123456789-align641234567890
[0078]
featuremap,其中bit_width=8
[0079]
由上表可知,数据未进行行对齐,连续存储数据,根据每次计算pixel的数目,计算出循环次数loop_num,最后一次(loop_num-1)mac计算需要搬运多余废数据,以保证搬运数据量64字节对齐;
[0080]
s3.3:基于nna,即基于硬件计算卷积相乘累加和,对max_pixel_num循环,对每个pixel进行mac计算,每次mac结果累加,得到最后所有pixel卷积结果;
[0081]
mac:
[0082]
累加:sum=temp0 temp1
……
tempn
[0083]
result=sum;
[0084]
s4:last_group,最后一次pixel循环,
[0085]
判断pixel循环是否为最后一次循环,如果是,则mac_pixel=pixel_num%max_pixel_num,无需搬运多余元素;如果不是,mac_pixel=max_pixel_num。
[0086]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明实施例可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
当前第1页1
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!