机器人的移动控制方法、装置、设备及存储介质与流程-j9九游会真人
1.本技术涉及人工智能技术领域,特别涉及一种机器人的移动控制方法、装置、设备及存储介质。
背景技术:
2.机器人的移动控制应用于各种场景中,涉及地面、空中、水下和外太空等场景。在工业领域,机器人的移动控制可以应用于仓储物流搬运、工厂不同工位物料运输、大型零件加工或者焊接、长距离物体检测抓取等场景,旨在提高工作效率,减少人力成本,以及减少工作的危险。
3.在研究机器人的移动控制方法时,往往采用在仿真环境中训练机器人的移动控制策略,再将该策略迁移到真实环境的方法。然而在仿真环境中学习到的策略由于存在sim to real gap(simulation-to-reality gap,模拟与现实之间的差距),通常无法直接迁移到真实环境中。因此,在相关技术中,通常对仿真环境进行随机化处理,即在仿真环境中加入必要的随机噪声,以模拟真实环境中的不确定性。
4.上述相关技术提供的在仿真环境中加入必要的随机噪声,这种方法非常依赖人类经验来设定随机噪声的类型和强度,因此可能会导致从仿真环境中迁移的移动控制策略在真实环境中的性能下降。
技术实现要素:
5.本技术实施例提供了一种机器人的移动控制方法、装置、设备及存储介质。本技术实施例提供的技术方案如下:
6.根据本技术实施例的一个方面,提供了一种机器人的移动控制方法,所述方法包括:
7.获取真实环境的状态信息,所述真实环境被划分为多个网格,所述真实环境中包括至少一个机器人,所述状态信息用于指示所述真实环境以及所述至少一个机器人的状态;
8.将所述状态信息输入至训练后的强化学习策略,所述强化学习策略经过在仿真环境中训练后直接迁移至所述真实环境使用;
9.通过所述强化学习策略根据所述状态信息,生成针对所述机器人的控制信息,所述控制信息用于控制所述机器人在所述网格之间进行移动。
10.根据本技术实施例的一个方面,提供了一种机器人的移动控制方法,所述方法包括:
11.获取仿真环境在第一时间单元的状态信息,所述仿真环境被划分为多个网格,所述仿真环境中包括至少一个仿真机器人,所述状态信息用于指示所述仿真环境以及所述至少一个仿真机器人的状态;
12.通过强化学习策略根据所述第一时间单元的状态信息,生成所述第一时间单元的
控制信息,所述控制信息用于控制所述仿真机器人在所述网格之间进行移动;
13.确定所述仿真机器人在执行所述第一时间单元的控制信息所指示的操作之后,所述仿真环境在第二时间单元的状态信息,所述第二时间单元是所述第一时间单元的下一个时间单元;
14.根据基于所述状态信息和所述动作信息计算得到的损失函数值,对所述强化学习策略的参数进行调整,得到训练后的强化学习策略;其中,所述训练后的强化学习策略用于直接迁移至真实环境中使用。
15.根据本技术实施例的一个方面,提供了一种机器人的移动控制装置,所述装置包括:
16.获取模块,用于获取真实环境的状态信息,所述真实环境被划分为多个网格,所述真实环境中包括至少一个机器人,所述状态信息用于指示所述真实环境以及所述至少一个机器人的状态;
17.输入模块,用于将所述状态信息输入至训练后的强化学习策略,所述强化学习策略经过在仿真环境中训练后直接迁移至所述真实环境使用;
18.生成模块,用于通过所述强化学习策略根据所述状态信息,生成针对所述机器人的控制信息,所述控制信息用于控制所述机器人在所述网格之间进行移动。
19.根据本技术实施例的一个方面,提供了一种机器人的移动控制装置,所述装置包括:
20.获取模块,用于获取仿真环境在第一时间单元的状态信息,所述仿真环境被划分为多个网格,所述仿真环境中包括至少一个仿真机器人,所述状态信息用于指示所述仿真环境以及所述至少一个仿真机器人的状态;
21.生成模块,用于通过强化学习策略根据所述第一时间单元的状态信息,生成所述第一时间单元的控制信息,所述控制信息用于控制所述仿真机器人在所述网格之间进行移动;
22.确定模块,用于确定所述仿真机器人在执行所述第一时间单元的控制信息所指示的操作之后,所述仿真环境在第二时间单元的状态信息,所述第二时间单元是所述第一时间单元的下一个时间单元;
23.调参模块,用于根据基于所述状态信息和所述动作信息计算得到的损失函数值,对所述强化学习策略的参数进行调整,得到训练后的强化学习策略;其中,所述训练后的强化学习策略用于直接迁移至真实环境中使用。
24.根据本技术实施例的一个方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有计算机程序,所述计算机程序由所述处理器加载并执行以实现上述机器人的移动控制方法。
25.根据本技术实施例的一个方面,提供了一种计算机可读存储介质,所述存储介质中存储有计算机程序,所述计算机程序由处理器加载并执行以实现上述机器人的移动控制方法。
26.根据本技术实施例的一个方面,提供了一种计算机程序产品,所述计算机程序产品包括计算机程序,所述计算机程序存储在计算机可读存储介质中,处理器从所述计算机可读存储介质读取并执行所述计算机程序,以实现上述机器人的移动控制方法。
27.本技术实施例提供的技术方案至少包括如下有益效果:
28.通过将环境划分为多个网格,然后通过强化学习策略根据状态信息生成用于控制机器人在上述网格之间移动的控制信息,这样就可以将机器人的动作简化为有限的控制指令,避免了由于域随机化处理的参数设置不合理和不足以覆盖真实环境多样性而导致的性能下降问题,达到了将强化学习策略从仿真环境直接迁移到真实环境中使用,而不影响其性能的技术效果。
附图说明
29.图1是本技术一个实施例提供的方案实施环境的示意图;
30.图2是本技术一个实施例提供的机器人的移动控制方法的流程图;
31.图3是本技术一个实施例提供的5种控制指令控制机器人移动的示意图;
32.图4是本技术一个实施例提供的同步执行和异步执行的示意图;
33.图5是本技术一个实施例提供的机器人速度控制的示意图;
34.图6是本技术另一个实施例提供的机器人的移动控制方法的流程图;
35.图7是本技术一个实施例提供的机器人的移动控制装置的示意图;
36.图8是本技术另一个实施例提供的机器人的移动控制装置的示意图;
37.图9是本技术一个实施例提供的计算机设备的结构框图。
具体实施方式
38.为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施方式作进一步地详细描述。
39.人工智能(artificial intelligence,简称ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
40.人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、预训练模型技术、操作/交互系统、机电一体化等技术。其中,预训练模型又称大模型、基础模型,经过微调后可以广泛应用于人工智能各大方向下游任务。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
41.机器学习(machine learning,简称ml)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、式教学习等技术。预训练模型是深度学习的最新发展成果,融合了以上技术。
42.随着人工智能技术研究和进步,人工智能技术在多个领域展开研究和应用,例如
常见的智能家居、智能穿戴设备、虚拟助理、智能音箱、智能营销、无人驾驶、自动驾驶、无人机、数字孪生、虚拟人、机器人、人工智能生成内容(artificial intelligence generated content,简称aigc)、对话式交互、智能医疗、智能客服、游戏ai等,相信随着技术的发展,人工智能技术将在更多的领域得到应用,并发挥越来越重要的价值。
43.本技术实施例提供的方案涉及人工智能的强化学习和机器人控制等技术,具体通过如下实施例进行说明。
44.请参考图1,其示出了本技术一个实施例提供的方案实施环境的示意图,该方案实施环境可以包括:第一设备10、第二设备20、控制设备30和至少一个机器人40。
45.第一设备10用于在仿真环境中对强化学习策略进行训练,得到训练后的强化学习策略。该训练后的强化学习策略用于直接迁移至真实环境中使用,实现对机器人进行移动控制。
46.第二设备20用于在真实环境中运行上述训练后的强化学习策略,通过该训练后的强化学习策略根据真实环境的状态信息,生成针对机器人40的控制信息,该控制信息用于控制机器人40在真实环境中进行移动。
47.上述第一设备10和第二设备20可以是同一设备,也可以是不同的设备,本技术对此不作限定。上述第一设备10和第二设备20可以是诸如pc(personal computer,个人计算机)、服务器等具备计算与存储能力的电子设备。
48.控制设备30用于对机器人40的移动进行控制。在一些实施例中,第二设备20生成的控制信息包括机器人40对应的控制指令,该控制指令可用于控制机器人40执行相应的操作,例如朝不同方向进行移动或者停止不移动。第二设备20可以将机器人40对应的控制指令发送给控制设备30,由控制设备30根据该控制指令对机器人40的移动进行控制。示例性地,控制设备30能够将机器人40对应的控制指令转换为对机器人40进行移动控制的移动指令(如包括速度或者其他信息),然后基于该移动指令对机器人40进行控制。
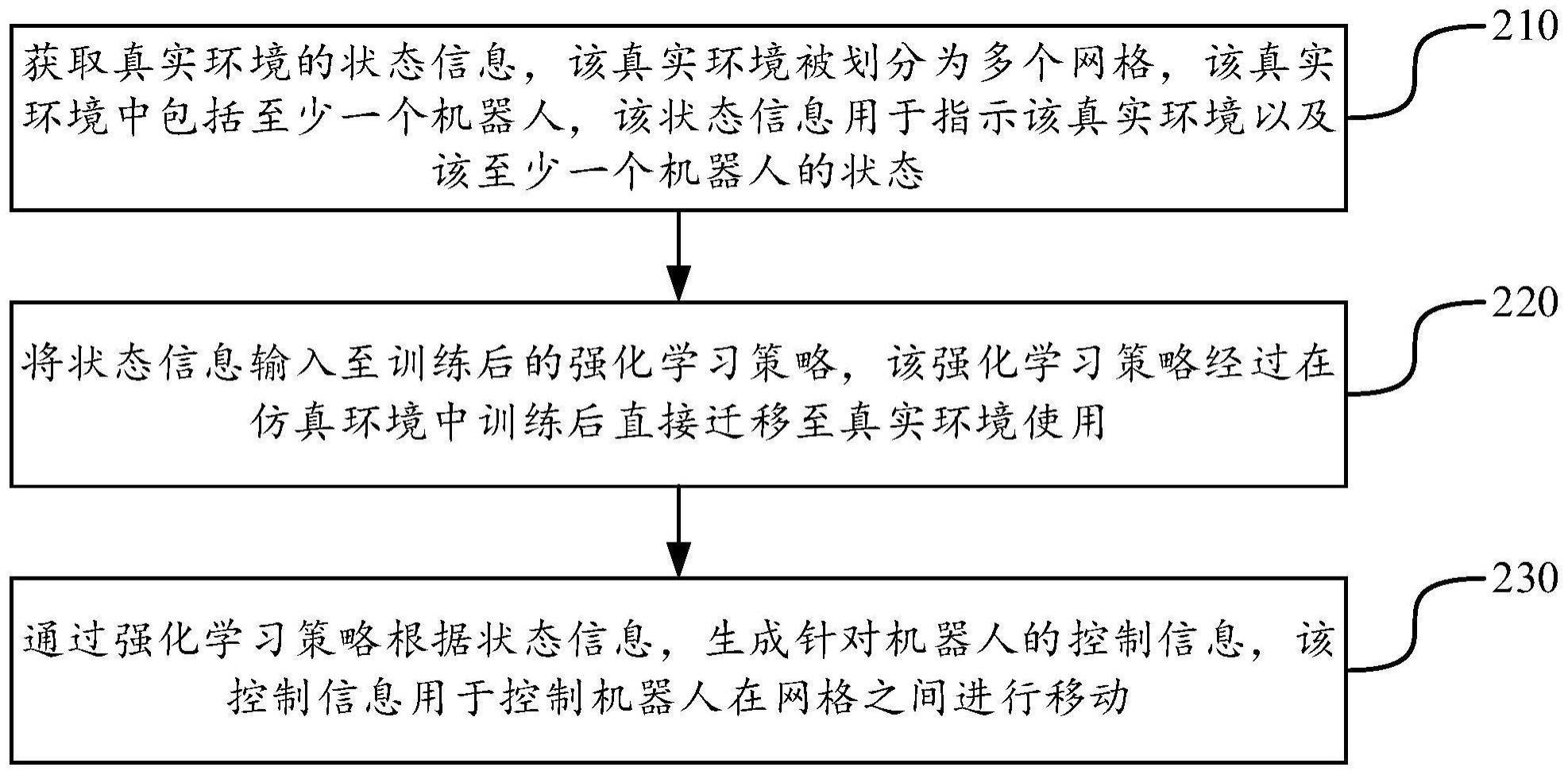
49.在一些实施例中,控制设备30可以独立于机器人40设置,例如控制设备30可以是能够与机器人40进行通信的独立的设备,诸如pc、手机、平板电脑、服务器等电子设备。
50.在一些实施例中,控制设备30也可以集成在机器人40上,例如控制设备30可以是安装在机器人40身上的控制器,该控制器具备信息处理以及控制机器人40进行操作的功能。
51.控制设备30的数量可以是一个,也可以是多个。一个控制设备30可以对一个机器人40的移动进行控制,也可以对多个机器人40的移动进行控制。
52.机器人40也可称为智能体或者其他名称。机器人40的数量可以是一个,也可以是多个。机器人40可以是一种能够感知环境、处理信息、执行任务的自动化设备,用于替代或辅助人类在各种领域和场景中完成工作或娱乐的目的。示例性地,机器人40可以是智能小车,即可以移动且能够对其移动进行控制的小车。示例性地,在仓储场景下,机器人40可以是用于搬运货物的机器人,也可以是仓储机器人、物流仓库巡视机器人等。当然,本技术技术方案除了可应用于仓储场景之外,还可应用于其他场景,如巡检场景、配送场景等,本技术对此不作限定。
53.此外,机器人40和/或机器人40所处的真实环境中可以设置用于采集该真实环境的状态信息的传感设备。示例性地,传感设备包括但不限于摄像头、距离传感器、速度传感
器、运动传感器、温度传感器等,其能够采集真实环境的状态以及真实环境中的机器人40的状态。上述状态信息可以由控制设备30汇总收集之后,发送给第二设备20,以便第二设备20能够根据状态信息生成针对机器人40的控制信息。
54.上述第二设备20与控制设备30之间可以进行通信,例如可以通过网络进行通信,如无线或有线网络。示例性地,第二设备20作为server(服务)端,控制设备30作为client(客户)端,两者之间可以采用ros(robot operating system,机器人操作系统)的actionlib(动作库)通信方式进行通信。
55.请参考图2,其示出了本技术一个实施例提供的机器人的移动控制方法的流程图。该方法各步骤的执行主体可以是计算机设备,例如该计算机设备可以是图1所示的方案实施环境中的第二设备20。该方法可以包括如下步骤210~230中的至少一个步骤。
56.步骤210,获取真实环境的状态信息,该真实环境被划分为多个网格,该真实环境中包括至少一个机器人,该状态信息用于指示该真实环境以及该至少一个机器人的状态。
57.真实环境是指机器人进行移动、操作和交互的物理环境。真实环境被划分为多个网格,该多个网格的尺寸可以相同。在一些实施例中,对真实环境中机器人所在的承载面进行网格划分,将该承载面划分为多个网格。示例性地,该承载面可以是平面,也可以是曲面,本技术对此不作限定。示例性地,承载面为承载平面,可以对该承载平面按照网格进行划分,得到多个网格。示例性地,承载面为承载曲面,在划分网格时,可以按照曲面在某平面上的投影来进行网格划分。网格的形状可以是矩形(如正方形),也可以是其他规则或者不规则的图形,本技术对此不作限定。示例性地,网格形状可以为矩形,被划分为n
×
m个网格,n和m可以相等,也可以不相等,n、m均为正整数。可选地,机器人在上述承载面上的投影的尺寸,要小于单个网格的尺寸。
58.真实环境中包括至少一个机器人是指该真实环境中可以有一个机器人,也可以有多个机器人,本技术对此不作限定。本技术实施例提供的技术方案,可以适用于对多个机器人进行联合控制的场景,也可以适用于对单个机器人进行独立控制的场景。
59.在一些实施例中,状态信息包括环境状态信息和机器人状态信息。其中,环境状态信息用于指示机器人所处的真实环境的状态。环境状态信息可以包括环境中物体的位置、尺寸、姿态、重量等信息中的至少一种。机器人状态信息用于指示机器人的状态。机器人状态信息可以包括机器人的位置、姿态、速度、加速度等信息中的至少一种。
60.在一些实施例中,状态信息至少包括强化学习策略所需要的全部信息。示例性地,在机器人搬运货物的场景中,机器人状态信息可以包括机器人的位置、姿态、速度、朝向、负载等信息中的至少一种,这些信息可以反映机器人的运动状态和任务状态。环境状态信息可以包括真实环境中的货物的位置、数量、重量、目标地点等信息中的至少一种,以及包括真实环境的地图、障碍物、通道等信息中的至少一种,这些信息可以反映货物的分布和需求以及真实环境的结构和限制。
61.在一种可能实现方式中,可以通过安装在真实环境和/或机器人上的传感设备获取上述状态信息。示例性地,可以通过摄像头、雷达、激光等传感设备,获取真实环境中的障碍物、人员、物体等信息;也可以通过安装在机器人身上的传感设备,获取机器人的位置、姿态、速度等信息。
62.步骤220,将状态信息输入至训练后的强化学习策略,该强化学习策略经过在仿真
环境中训练后直接迁移至真实环境使用。
63.强化学习策略是指机器人与环境交互并做出行动决策的规则。在本技术实施例中,强化学习策略在仿真环境中进行训练,得到训练后的强化学习策略,该强化学习策略在仿真环境中的训练过程,可参考下文实施例中的介绍说明。另外,训练后的强化学习策略从仿真环境中直接迁移至真实环境使用,也就是说,在真实环境中不需要再对该训练后的强化学习策略的参数做进一步的调整。
64.步骤230,通过强化学习策略根据状态信息,生成针对机器人的控制信息,该控制信息用于控制机器人在网格之间进行移动。
65.在一些实施例中,该强化学习策略可以基于神经网络构建,其输入数据包括状态信息,输出数据包括各个机器人各自的动作信息,该动作信息可以包括若干个候选的动作的概率。根据各个机器人各自的动作信息,可以得到针对机器人的控制信息。
66.在一些实施例中,控制信息包括至少一个机器人分别对应的控制指令。对于每一个机器人来说,该机器人对应的控制指令用于控制机器人执行的动作。可选地,控制指令可以包括机器人的运动参数,也可以包括机器人的目标位置。示例性地,控制指令可以是向前移动、加速度或让机器人向前移动一定的距离等。
67.在一些实施例中,控制指令用于控制机器人执行以下操作中的一种:向前移动、向后移动、向左移动、向右移动、停止。其中,向前移动是指沿着机器人的朝向的正前方移动,向后移动是指沿着机器人的朝向的正后方移动,向左移动是指沿着机器人的左侧方向移动,向右移动是指沿着机器人的右侧方向移动,停止是指保持机器人当前所在位置不变。
68.结合上文介绍的对真实环境进行了网格划分,向前移动是指沿着机器人的朝向的正前方,从机器人当前所处的网格移动到其正前方的一个网格中;向后移动是指沿着机器人的朝向的正后方,从机器人当前所处的网格移动到其正后方的一个网格中;向左移动是指沿着机器人的左侧方向,从机器人当前所处的网格移动到其左侧方向的一个网格中;向右移动是指沿着机器人的右侧方向,从机器人当前所处的网格移动到其右侧方向的一个网格中;停止是指保持机器人当前所处的网格不变,不进行移动。
69.如图3所示,其示出了本技术一个实施例提供的控制指令控制机器人移动的示意图。在图3中,白色圆点表示机器人原始的位置,黑色圆点表示机器人移动至的位置。图3的子图(a)表示控制机器人向前移动,图3的子图(b)表示控制机器人向后移动,图3的子图(c)表示控制机器人向左移动,图3的子图(d)表示控制机器人向右移动,图3的子图(e)表示控制机器人停止,保持不动。
70.由于在本技术实施例中,对真实环境进行了网格划分,因此强化学习策略输出的动作信息也可以得到简化,如仅需包括向前移动、向后移动、向左移动、向右移动、停止这5个候选的动作的概率。对于每一个机器人来说,可以根据该机器人对应的动作信息中包括的上述5个候选的动作的概率,将概率最大的动作确定为该机器人对应的控制指令。例如,真实环境中包括2个机器人,记为第一机器人和第二机器人,其中第一机器人对应的动作信息中包括的上述5个候选的动作的概率依次为0.8、0.05、0.05、0.05和0.05,则将概率最大的动作(即向前移动)确定为该机器人对应的控制指令。
71.在一些实施例中,上述步骤230之后还包括:对于每一个机器人,向该机器人对应的控制设备发送该机器人对应的控制指令,该控制指令用于转换为对该机器人进行移动控
制的速度。其中,机器人对应的控制设备负责将接收到的控制指令转换为机器人实际运行的线速度与角速度,然后控制机器人按照该线速度与角速度进行移动。示例性地,将控制指令转换为速度所采用的转换算法:包括但不限于以下任意一种:pid(proportion integration differentiation,比例-积分-微分)控制算法、lqr(linear quadratic regulator,线性二次型调节器)控制算法等。
72.综上所述,本技术实施例提供的技术方案,通过将环境划分为多个网格,然后通过强化学习策略根据状态信息生成用于控制机器人在上述网格之间移动的控制信息,这样就可以将机器人的动作简化为有限的控制指令,避免了由于域随机化处理的参数设置不合理和不足以覆盖真实环境多样性而导致的性能下降问题,达到了将强化学习策略从仿真环境直接迁移到真实环境中使用,而不影响其性能的技术效果。
73.对于真实环境中包括多个机器人的场景,该多个机器人可以同步执行各自对应的控制指令,也可以异步执行各自对应的控制指令。
74.所谓多个机器人同步执行各自对应的控制指令,是指当该多个机器人均完成本阶段的控制指令之后,再同时执行下一阶段的控制指令。由于机器人执行不同控制指令的耗时不同,即便同一个机器人每次执行相同的控制指令所花费的时间也会由于机器人自身状态的差异而不同,这种同步执行的方式会导致机器人之间存在非工作期,即某些机器人处于等待状态而不能执行任务的空档期,整个系统执行一次指令的时间长度由所有机器人执行各自的控制指令的最长耗时来决定,这个严重影响了整个系统的工作效率。
75.针对该问题,本技术实施例提出了一种异步执行的方式。所谓多个机器人异步执行各自对应的控制指令,是指每个机器人根据自身的控制指令按照各自的进度独立执行任务,而不是等待其它机器人完成再统一执行,即每个机器人实现各自控制指令的异步执行。这种异步执行的方式,可有效减少或避免系统中机器人的非工作空档期,提升了整个系统的工作效率。
76.在一些实施例中,当多个机器人中的第一机器人,在第一时间单元完成第一机器人对应的控制指令时,获取真实环境在第一时间单元的状态信息;通过强化学习策略根据第一时间单元的状态信息,生成第一机器人在第二时间单元对应的控制指令,第二时间单元是第一时间单元的下一个时间单元。其中,第一机器人可以是上述多个机器人中的任意一个机器人。时间单元是指时域的划分单位,时间单元的长度可以结合实际情况进行设定,本技术对此不作限定。例如时间单元以秒为粒度进行划分,1秒为1个时间单元,或者5秒为一个时间单元;或者,时间单元以毫秒为粒度进行划分,100毫秒为1个时间单元,或者200毫秒为一个时间单元,等等。
77.如图4所示,其示出了同步执行和异步执行的示意图。在图4中,以机器人a和机器人b为例,对此进行说明。
78.对于同步执行的方式,控制指令1用于控制机器人a和机器人b分别执行各自对应的动作,从图中可以看出,机器人a执行该控制指令1对应的动作需要4个时间单元,机器人b执行该控制指令1对应的动作仅需2个时间单元,机器人b在执行完该控制指令1对应的动作之后,需要等待机器人a,待机器人a也完成该控制指令1对应的动作之后,再计算和下发下一个控制指令2。类似地,机器人a执行该控制指令2对应的动作仅需2个时间单元,机器人b执行该控制指令2对应的动作需要4个时间单元,机器人a在执行完该控制指令2对应的动作
之后,需要等待机器人b,待机器人b也完成该控制指令2对应的动作之后,再计算和下发下一个控制指令3。
79.对于异步执行的方式,控制指令1用于控制机器人a和机器人b分别执行各自对应的动作,从图中可以看出,机器人a执行该控制指令1对应的动作需要4个时间单元,机器人b执行该控制指令1对应的动作仅需2个时间单元。与同步执行的方式所不同的是,当机器人b执行完该控制指令1对应的动作之后,无需等待机器人a,直接计算和下发控制指令2,该控制指令2用于控制机器人b执行该控制指令2对应的动作。机器人b执行该控制指令2对应的动作需要4个时间单元,在机器人b执行该控制指令2对应的动作的过程中,机器人a执行完成上述控制指令1对应的动作,此时也无需等待机器人b,直接计算和下发控制指令3,该控制指令3用于控制机器人a执行该控制指令3对应的动作。从图中可以明显看出,异步执行的方式不会存在等待的耗时。
80.相较于采用同步执行方式的多机器人控制系统,本技术实施例提出的异步执行方式具有明显的效率优势。采用异步执行方式时,多个机器人之间可实现并行工作,即每个机器人可自主地、没有等待即可执行各自的控制指令,从而可以最大限度地利用系统资源,减少机器人之间的等待空档期,显著提升整个系统的工作效率。此外,异步执行方式还提高了系统的灵活性。在该方式下,每个机器人可根据其自身所处环境的变化或其自身状态的调整来更新执行程序,而不受其他机器人的影响。另外,机器人之间采用异步协同的方式可简化它们之间的协调过程,每个机器人仅需负责其对应任务的执行,无需与其他机器人进行复杂的协作,从而提高了系统的鲁棒性。具体而言,当系统中的某一机器人出现故障时,不会影响或拖延组内其他机器人各自任务的执行进度。综上所述,异步执行方式可显著提升多机器人协同系统的效率、灵活性与鲁棒性。
81.在上文实施例中,由于机器人按照网格移动,且移动方向只能是前、后、左、右,导致机器人到达一个网格之后,其速度为0,造成机器人在直行过程中会出现一顿一顿的情况。对此,可以通过仿真超前模拟推理的方式,通过判断机器人下两步动作的方向是否是同一方向,从而控制机器人到达下一个网格之后的速度是否需要降为0。
82.在一个实施例中,通过强化学习策略根据状态信息,得到至少两步动作信息,每一步动作信息包括至少一个机器人分别对应的动作数据,该动作数据用于指示该机器人是否移动以及在移动的情况下机器人的移动方向;根据至少两步动作信息,确定下一步的控制信息,下一步的控制信息包括至少一个机器人分别对应的控制指令,该控制指令包括方向控制指令和速度控制指令,该方向控制指令用于指示机器人是否移动以及在移动的情况下机器人的移动方向,该速度控制指令用于指示机器人移动至下一个网格后的速度是否变为零。示例性地,方向控制指令用于指示机器人向前移动、向后移动、向左移动、向右移动、停止中的任意一种。示例性地,速度控制指令用于指示机器人移动至下一个网格后的速度变为0,或者不变为0。
83.为了得到机器人至少两步动作信息,实现步骤是通过强化学习策略根据状态信息,得到下一步的动作信息;根据下一步的动作信息,预测得到真实环境的新的状态信息;其中,该新的状态信息是真实环境在机器人执行下一步的动作信息之后的状态信息;通过强化学习策略根据该新的状态信息,得到再下一步的动作信息。其中,根据下一步的动作信息,预测得到真实环境的新的状态信息可以通过如下方式实现:构建与真实环境的状态信
息相一致的仿真环境,在仿真环境中控制仿真机器人执行下一步的动作信息,在执行完成之后获取仿真环境的状态信息,作为预测得到的真实环境的新的状态信息。当然,在一些其他可能的实施例中,也可以通过直接数值计算或者基于神经网络模型的预测等方式,根据下一步的动作信息,预测得到真实环境的新的状态信息,本技术对此不作限定。
84.另外,根据至少两步动作信息,确定下一步的控制信息,包括如下子步骤:对于每一个机器人,获取机器人的第一动作数据和第二动作数据;其中,第一动作数据是指下一步的动作信息中包括的机器人对应的动作数据,第二动作数据是指再下一步的动作信息中包括的机器人对应的动作数据。
85.若第一动作数据和第二动作数据均指示机器人移动且移动方向相同,则将第一动作数据确定为机器人对应的方向控制指令,以及确定机器人对应的速度控制指令为指示机器人移动至下一个网格后的速度不变为零。
86.若第一动作数据和第二动作数据中的至少之一指示机器人不移动,或者第一动作数据和第二动作数据均指示机器人移动且移动方向不同,则将第一动作数据确定为机器人对应的方向控制指令,以及确定机器人对应的速度控制指令为指示机器人移动至下一个网格后的速度变为零。
87.根据各个机器人对应的方向控制指令和速度控制指令,得到下一步的控制信息。
88.如图5所示,其示出了机器人速度控制的示意图。在优化前,控制指令为到达下一个网格后速度为0,这就会造成机器人在直行过程中会出现一顿一顿的情况。在优化后,如果预测机器人在接下去2步中是朝同一个方向移动,则控制指令为到达下一个网格,且不再要求速度为0。当然,如果存在转弯,则仍然会将速度控制到0再转弯,这也符合常规直觉。使用上述优化方案后,机器人的移动过程变的丝滑连贯,不再有卡顿的情况出现。而且,我们在实验中给定了一个搬运物体的任务,从一开始一格一格运动到使用了上述优化方案后,时间从2分36秒加速到55秒,运行效率是原先的2.8倍,有了明显提升。
89.通过上述方式,基于多步动作预测的速度控制方法可以有效减少机器人直行过程中的速度抖动,使运动更加平滑连贯。充分利用强化学习策略的多步推理优势,实现了对机器人速度的精确控制,降低了积累误差,提高了运动精度。同时,减少了不必要的加速减速,节省了能源消耗。提出的控制方案计算量小、实时性强,易于工程实现。
90.上文实施例介绍了在真实环境中应用训练后的强化学习策略对机器人进行移动控制的方案,下面将通过实施例介绍该强化学习策略在仿真环境中的训练过程。对于强化学习策略的应用和训练,两者是相关联的,在一侧实施例中未做详细说明的细节,可参见另一侧实施例中的介绍说明。
91.请参考图6,其示出了本技术另一个实施例提供的机器人的移动控制方法的流程图。该方法各步骤的执行主体可以是计算机设备,例如该计算机设备可以是图1所示的方案实施环境中的第一设备10。该方法可以包括如下步骤610~640中的至少一个步骤。
92.步骤610,获取仿真环境在第一时间单元的状态信息,仿真环境被划分为多个网格,仿真环境中包括至少一个仿真机器人,状态信息用于指示仿真环境以及至少一个仿真机器人的状态。
93.仿真环境是指构建的虚拟机器人运动场景,用于替代真实环境对控制算法进行开发、调试、验证和优化。仿真环境和真实环境一样,都被划分为多个网格。仿真环境中的网格
的尺寸,与真实环境中的网格的尺寸可以相同,这有助于提升强化学习策略从仿真环境迁移到真实环境之后的性能。
94.仿真环境中的仿真机器人是用于模拟真实环境中的机器人的模型。仿真机器人与真实机器人可以具有相同的结构、属性参数、能力、数量等,从而使得仿真环境与真实环境更加地接近,有助于提升强化学习策略从仿真环境迁移到真实环境之后的性能。
95.另外,对于网格划分以及状态信息的介绍说明,可参见上文实施例,此处不再赘述。
96.步骤620,通过强化学习策略根据第一时间单元的状态信息,生成第一时间单元的控制信息,控制信息用于控制仿真机器人在网格之间进行移动。
97.在一些实施例中,控制信息包括至少一个仿真机器人分别对应的控制指令,控制指令用于控制仿真机器人执行以下操作中的一种:向前移动、向后移动、向左移动、向右移动、停止。
98.在一些实施例中,强化学习策略基于mdp(markov decision process,马尔可夫决策过程),实现步骤如下:首先构建mdp模型,包括定义状态空间、动作空间、奖励函数、动态转移函数等,抽象描述实际问题;接着设计强化学习算法,根据不同类型的mdp,选择合适的算法,本技术对此算法不做限定,例如,dqn(deep q network,深度q网络)、策略梯度等;再更新策略,让机器人与环境交互执行动作,算法更新策略或者价值函数;重复上述步骤,机器人多次与环境交互学习,逐步提升策略。在训练结束时,获得一个可导致最大期望收益的策略。在一种可能实现的方式中,利用dqn学习算法训练强化学习模型。首先,构建一个深度神经网络来拟合q函数,并初始化网络参数以及一些算法超参数,比如学习率等。接下来,机器人会与环境进行交互,执行动作并获得状态、奖励的反馈,将这些状态转移数据存储起来。然后从存储的数据中随机取出一部分,计算执行某个动作后应该能够得到的目标q值,同时让网络预测这个状态动作的当前q值,两者的差异即为损失函数。通过不断进行反向传播更新网络参数以最小化损失函数,这样可以逐步提升网络预测q值的效果。重复训练多个回合,最终我们可以得到一个经过良好训练的dqn模型,以生成控制仿真机器人在网格间移动的最佳控制信息。
99.在一些实施例中,为了方便强化学习策略直接迁移到真实环境中,在仿真环境也需要对机器人移动轨迹是直行的操作进行处理,因此在生成第一时间单元的控制信息时,也要依据机器人两步动作信息,具体步骤如下:
100.通过强化学习策略根据第一时间单元的状态信息,得到至少两步动作信息,每一步动作信息包括至少一个仿真机器人分别对应的动作数据,动作数据用于指示仿真机器人是否移动以及在移动的情况下仿真机器人的移动方向;
101.根据至少两步动作信息,确定第一时间单元的控制信息,第一时间单元的控制信息包括至少一个仿真机器人分别对应的控制指令,控制指令包括方向控制指令和速度控制指令,方向控制指令用于指示仿真机器人是否移动以及在移动的情况下仿真机器人的移动方向,速度控制指令用于指示仿真机器人移动至下一个网格后的速度是否变为零。
102.在一些实施例中,确定至少两步动作信息包括如下步骤:通过强化学习策略根据第一时间单元的状态信息,得到第一时间单元的动作信息;根据第一时间单元的动作信息,确定仿真环境在第二时间单元的状态信息;其中,第二时间单元的状态信息是仿真环境在
仿真机器人执行第一时间单元的动作信息之后的状态信息;通过强化学习策略根据第二时间单元的状态信息,得到第二时间单元的动作信息。
103.在一些实施例中,根据至少两步动作信息,确定第一时间单元的控制信息,包括如下步骤:对于每一个仿真机器人,获取仿真机器人的第一动作数据和第二动作数据;其中,第一动作数据是指第一时间单元的动作信息中包括的仿真机器人对应的动作数据,第二动作数据是指第二时间单元的动作信息中包括的仿真机器人对应的动作数据;若第一动作数据和第二动作数据均指示所述仿真机器人移动且移动方向相同,则将第一动作数据确定为所述仿真机器人对应的方向控制指令,以及确定仿真机器人对应的速度控制指令为指示仿真机器人移动至下一个网格后的速度不变为零;若第一动作数据和第二动作数据中的至少之一指示仿真机器人不移动,或者第一动作数据和所述第二动作数据均指示仿真机器人移动且移动方向不同,则将第一动作数据确定为仿真机器人对应的方向控制指令,以及确定仿真机器人对应的速度控制指令为指示仿真机器人移动至下一个网格后的速度变为零;根据各个仿真机器人对应的方向控制指令和速度控制指令,得到第一时间单元的控制信息。
104.在一些实施例中,当系统包括多个机器人的情况下,为了提升系统执行的效率,在仿真环境中,实现异步执行的方法。由于这个异步执行方法实际上已经改变了环境的动态转移函数,使得真实环境这部分的转移和仿真环境中存在差异,因此需要对仿真环境添加相应的域随机化处理,以一定概率不执行当前的控制指令,这样学习出来的强化学习策略能够泛化到真实环境。
105.域随机化是一种数据增强技术,是在训练期间,通过在仿真环境中引入随机性,让训练得到的强化学习策略适应更加广泛的状态,而不仅仅过度优化在固定仿真环境上的表现。常用于提高强化学习中学到的策略从仿真环境向真实环境的泛化能力。
106.该域随机化处理包括:随机确定多个仿真机器人分别对应的概率值,该概率值用于确定仿真机器人执行或不执行对应的控制指令;对于需要执行对应的控制指令的仿真机器人,根据第一时间单元的控制信息控制仿真机器人执行对应的控制指令;其中,对于不需要执行对应的控制指令的仿真机器人,不控制仿真机器人执行对应的控制指令;在仿真机器人执行对应的控制指令之后,获取仿真环境在第二时间单元的状态信息。
107.步骤630,确定仿真机器人在执行第一时间单元的控制信息所指示的操作之后,该仿真环境在第二时间单元的状态信息,第二时间单元是第一时间单元的下一个时间单元。
108.仿真机器人的移动轨迹是一个网格一个网格移动,执行第一时间单元的操作后,仿真环境的状态信息(包括仿真环境和仿真机器人的状态)会相应地发生改变,通过确定下一个时间单元(即第二时间单元)的状态信息,再利用强化学习策略推理出第二时间单元的控制信息,以此循环。
109.步骤640,根据基于状态信息和动作信息计算得到的损失函数值,对强化学习策略的参数进行调整,得到训练后的强化学习策略;其中,训练后的强化学习策略用于直接迁移至真实环境中使用。
110.强化学习的目标是最大化长期累积的奖励。为此,机器人需要在与环境交互的过程中,逐步调整策略,使其越来越逼近能够获得最大累积奖励的最优策略。基于预先定义好的环境模型,设计各种损失函数来指导策略的调整和优化。损失函数的设计可以根据不同的算法和具体任务进行灵活调整,最终目的是不断提升期望累积奖励或策略的表现。例如,
可以使用均方误差、交叉熵、时序差分误差等不同形式的损失函数。对强化学习中策略的参数调整也有多种可选方式。最常见的是通过梯度下降法最小化设计好的损失函数来更新参数,但也可以采用直接沿策略梯度方向调整参数的方法,或者在actor-critic(执行者-评判者)框架下分别更新策略和价值函数。总之,强化学习参数调整的技术手段很多,不应限定在某一特定方法上,可以根据实际需要进行设计和选择。但其共同终极目标都是学习到一个对环境尽可能高奖励的稳定策略。
111.综上所述,本技术实施例提供的技术方案,通过将仿真环境划分为多个网格,然后在该仿真环境下训练用于控制机器人移动的强化学习策略,这样就可以将机器人的动作简化为有限的控制指令,避免了由于域随机化处理的参数设置不合理和不足以覆盖真实环境多样性而导致的性能下降问题,达到了将强化学习策略从仿真环境直接迁移到真实环境中使用,而不影响其性能的技术效果。
112.另外,在对多个机器人的移动进行异步控制时,在仿真环境中加入不执行当前控制指令的随机概率,很好地贴合了真实环境中由于环境的不确定性带来的误差。
113.下述为本技术装置实施例,可以用于执行本技术方法实施例。对于本技术装置实施例中未披露的细节,请参照本技术方法实施例。
114.请参照图7,其示出了本技术一个实施例提供的机器人的移动控制装置的框图。该装置具有实现上述机器人的移动控制方法的功能,所述功能可以由硬件实现,也可以由硬件执行相应的软件实现。该装置可以是计算机设备,也可以设置在计算机设备中。该装置700可以包括:获取模块710、输入模块720和生成模块730。
115.获取模块710,用于获取真实环境的状态信息,所述真实环境被划分为多个网格,所述真实环境中包括至少一个机器人,所述状态信息用于指示所述真实环境以及所述至少一个机器人的状态。
116.输入模块720,用于将所述状态信息输入至训练后的强化学习策略,所述强化学习策略经过在仿真环境中训练后直接迁移至所述真实环境使用。
117.生成模块730,用于通过所述强化学习策略根据所述状态信息,生成针对所述机器人的控制信息,所述控制信息用于控制所述机器人在所述网格之间进行移动。
118.在一些实施例中,所述控制信息包括所述至少一个机器人分别对应的控制指令,所述控制指令用于控制所述机器人执行以下操作中的一种:向前移动、向后移动、向左移动、向右移动、停止。
119.在一些实施例中,如图7所示,所述装置700还包括:发送模块740。
120.发送模块740,用于对于每一个机器人,向所述机器人对应的控制设备发送所述机器人对应的控制指令,所述控制指令用于转换为对所述机器人进行移动控制的速度。
121.在一些实施例中,所述机器人的数量为多个,多个所述机器人异步执行各自对应的控制指令。
122.所述获取模块710,还用于当多个所述机器人中的第一机器人,在第一时间单元完成所述第一机器人对应的控制指令时,获取所述真实环境在所述第一时间单元的状态信息。
123.所述生成模块730,还用于通过所述强化学习策略根据所述第一时间单元的状态信息,生成所述第一机器人在第二时间单元对应的控制指令,所述第二时间单元是所述第
一时间单元的下一个时间单元。
124.在一些实施例中,所述生成模块730,包括:获取单元和确定单元(图7中未示出)。
125.获取单元,用于通过所述强化学习策略根据所述状态信息,得到至少两步动作信息,每一步动作信息包括所述至少一个机器人分别对应的动作数据,所述动作数据用于指示所述机器人是否移动以及在移动的情况下所述机器人的移动方向。
126.确定单元,用于根据所述至少两步动作信息,确定下一步的控制信息,所述下一步的控制信息包括所述至少一个机器人分别对应的控制指令,所述控制指令包括方向控制指令和速度控制指令,所述方向控制指令用于指示所述机器人是否移动以及在移动的情况下所述机器人的移动方向,所述速度控制指令用于指示所述机器人移动至下一个网格后的速度是否变为零。
127.在一些实施例中,所述获取单元用于:通过所述强化学习策略根据所述状态信息,得到下一步的动作信息;根据所述下一步的动作信息,预测得到所述真实环境的新的状态信息;其中,所述新的状态信息是所述真实环境在所述机器人执行所述下一步的动作信息之后的状态信息;通过所述强化学习策略根据所述新的状态信息,得到再下一步的动作信息。
128.在一些实施例中,所述确定单元用于:对于每一个机器人,获取所述机器人的第一动作数据和第二动作数据;其中,所述第一动作数据是指所述下一步的动作信息中包括的所述机器人对应的动作数据,所述第二动作数据是指所述再下一步的动作信息中包括的所述机器人对应的动作数据;若所述第一动作数据和所述第二动作数据均指示所述机器人移动且移动方向相同,则将所述第一动作数据确定为所述机器人对应的方向控制指令,以及确定所述机器人对应的速度控制指令为指示所述机器人移动至下一个网格后的速度不变为零;若所述第一动作数据和所述第二动作数据中的至少之一指示所述机器人不移动,或者所述第一动作数据和所述第二动作数据均指示所述机器人移动且移动方向不同,则将所述第一动作数据确定为所述机器人对应的方向控制指令,以及确定所述机器人对应的速度控制指令为指示所述机器人移动至下一个网格后的速度变为零;根据各个所述机器人对应的方向控制指令和速度控制指令,得到所述下一步的控制信息。
129.请参照图8,其示出了本技术另一个实施例提供的机器人的移动控制装置的框图。该装置具有实现上述机器人的移动控制方法的功能,所述功能可以由硬件实现,也可以由硬件执行相应的软件实现。该装置可以是计算机设备,也可以设置在计算机设备中。该装置800可以包括:获取模块810、生成模块820、确定模块830和调参模块840。
130.获取模块810,用于获取仿真环境在第一时间单元的状态信息,所述仿真环境被划分为多个网格,所述仿真环境中包括至少一个仿真机器人,所述状态信息用于指示所述仿真环境以及所述至少一个仿真机器人的状态。
131.生成模块820,用于通过强化学习策略根据所述第一时间单元的状态信息,生成所述第一时间单元的控制信息,所述控制信息用于控制所述仿真机器人在所述网格之间进行移动。
132.确定模块830,用于确定所述仿真机器人在执行所述第一时间单元的控制信息所指示的操作之后,所述仿真环境在第二时间单元的状态信息,所述第二时间单元是所述第一时间单元的下一个时间单元。
133.调参模块840,用于根据基于所述状态信息和所述动作信息计算得到的损失函数值,对所述强化学习策略的参数进行调整,得到训练后的强化学习策略;其中,所述训练后的强化学习策略用于直接迁移至真实环境中使用。
134.在一些实施例中,所述控制信息包括所述至少一个仿真机器人分别对应的控制指令,所述控制指令用于控制所述仿真机器人执行以下操作中的一种:向前移动、向后移动、向左移动、向右移动、停止。
135.在一些实施例中,所述仿真机器人的数量为多个,所述确定模块830,用于:
136.随机确定多个所述仿真机器人分别对应的概率值,所述概率值用于确定所述仿真机器人执行或不执行对应的控制指令;
137.对于需要执行对应的控制指令的仿真机器人,根据所述第一时间单元的控制信息控制所述仿真机器人执行对应的控制指令;其中,对于不需要执行对应的控制指令的仿真机器人,不控制所述仿真机器人执行对应的控制指令;
138.在所述仿真机器人执行对应的控制指令之后,获取所述仿真环境在所述第二时间单元的状态信息。
139.在一些实施例中,所述生成模块820,包括:获取单元和确定单元(图8中未示出)。
140.获取单元,用于通过所述强化学习策略根据所述第一时间单元的状态信息,得到至少两步动作信息,每一步动作信息包括所述至少一个仿真机器人分别对应的动作数据,所述动作数据用于指示所述仿真机器人是否移动以及在移动的情况下所述仿真机器人的移动方向。
141.确定单元,用于根据所述至少两步动作信息,确定所述第一时间单元的控制信息,所述第一时间单元的控制信息包括所述至少一个仿真机器人分别对应的控制指令,所述控制指令包括方向控制指令和速度控制指令,所述方向控制指令用于指示所述仿真机器人是否移动以及在移动的情况下所述仿真机器人的移动方向,所述速度控制指令用于指示所述仿真机器人移动至下一个网格后的速度是否变为零。
142.在一些实施例中,所述获取单元用于:通过所述强化学习策略根据所述第一时间单元的状态信息,得到所述第一时间单元的动作信息;根据所述第一时间单元的动作信息,确定所述仿真环境在所述第二时间单元的状态信息;其中,所述第二时间单元的状态信息是所述仿真环境在所述仿真机器人执行所述第一时间单元的动作信息之后的状态信息;通过所述强化学习策略根据所述第二时间单元的状态信息,得到所述第二时间单元的动作信息。
143.在一些实施例中,所述确定单元用于:对于每一个仿真机器人,获取所述仿真机器人的第一动作数据和第二动作数据;其中,所述第一动作数据是指所述第一时间单元的动作信息中包括的所述仿真机器人对应的动作数据,所述第二动作数据是指所述第二时间单元的动作信息中包括的所述仿真机器人对应的动作数据;若所述第一动作数据和所述第二动作数据均指示所述仿真机器人移动且移动方向相同,则将所述第一动作数据确定为所述仿真机器人对应的方向控制指令,以及确定所述仿真机器人对应的速度控制指令为指示所述仿真机器人移动至下一个网格后的速度不变为零;若所述第一动作数据和所述第二动作数据中的至少之一指示所述仿真机器人不移动,或者所述第一动作数据和所述第二动作数据均指示所述仿真机器人移动且移动方向不同,则将所述第一动作数据确定为所述仿真机
器人对应的方向控制指令,以及确定所述仿真机器人对应的速度控制指令为指示所述仿真机器人移动至下一个网格后的速度变为零;根据各个所述仿真机器人对应的方向控制指令和速度控制指令,得到所述第一时间单元的控制信息。
144.需要说明的是,上述实施例提供的装置,在实现其功能时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的装置与方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
145.请参考图9,其示出了本技术一个实施例提供的计算机设备900的结构框图。
146.通常,计算机设备900包括有:处理器910和存储器920。
147.处理器910可以包括一个或多个处理核心,比如4核心处理器、8核心处理器等。处理器910可以采用dsp(digital signal processing,数字信号处理)、fpga(field programmable gate array,现场可编程门阵列)、pla(programmable logic array,可编程逻辑阵列)中的至少一种硬件形式来实现。处理器910也可以包括主处理器和协处理器,主处理器是用于对在唤醒状态下的数据进行处理的处理器,也称cpu(central processing unit,中央处理器);协处理器是用于对在待机状态下的数据进行处理的低功耗处理器。在一些实施例中,处理器910可以在集成有gpu(graphics processing unit,图像处理器),gpu用于负责显示屏所需要显示的内容的渲染和绘制。一些实施例中,处理器910还可以包括ai处理器,该ai处理器用于处理有关机器学习的计算操作。
148.存储器920可以包括一个或多个计算机可读存储介质,该计算机可读存储介质可以是非暂态的。存储器920还可包括高速随机存取存储器,以及非易失性存储器,比如一个或多个磁盘存储设备、闪存存储设备。在一些实施例中,存储器920中的非暂态的计算机可读存储介质用于存储计算机程序,所述计算机程序经配置以由一个或者一个以上处理器执行,以实现上述机器人的移动控制方法。
149.本领域技术人员可以理解,图9中示出的结构并不构成对计算机设备900的限定,可以包括比图示更多或更少的组件,或者组合某些组件,或者采用不同的组件布置。
150.在一些实施例中,还提供了一种计算机可读存储介质,所述存储介质中存储有计算机程序,所述计算机程序由处理器加载并执行以实现上述机器人的移动控制方法。
151.可选地,该计算机可读存储介质可以包括:rom(read-only memory,只读存储器)、ram(random-access memory,随机存储器)、ssd(solid state drives,固态硬盘)或光盘等。其中,随机存取记忆体可以包括reram(resistance random access memory,电阻式随机存取记忆体)和dram(dynamic random access memory,动态随机存取存储器)。
152.在一些实施例中,还提供了一种计算机程序产品,所述计算机程序产品包括计算机程序,所述计算机程序存储在计算机可读存储介质中,处理器从所述计算机可读存储介质读取并执行所述计算机程序,以实现上述机器人的移动控制方法。
153.应当理解的是,在本文中提及的“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。另外,本文中描述的步骤编号,仅示例性示出了步骤间的一种可能的执行先后顺序,在一些其它实施
例中,上述步骤也可以不按照编号顺序来执行,如两个不同编号的步骤同时执行,或者两个不同编号的步骤按照与图示相反的顺序执行,本技术实施例对此不作限定。
154.以上所述仅为本技术的示例性实施例,并不用以限制本技术,凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
当前第1页1
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!