一种基于可复用booth乘法单元的存内计算电路-j9九游会真人
一种基于可复用booth乘法单元的存内计算电路
技术领域
1.本发明属于集成电路技术领域,具体的说是一种基于可复用booth乘法单元的存内计算电路。
背景技术:
2.近年来,人工智能领域发展迅速,各种模型的参数不断增多,对于硬件算力的要求不断提高。在图像、视频、音频处理等领域,各种人工智能模型发挥出不同的优势,但都对运算速度有着较高的要求。
3.然而,如今硬件算力的发展速度已逐渐跟不上算法的发展速度。以大规模的卷积神经网络为例,由于卷积层和全连接层中存在大量的权重需要进行大量的卷积运算,卷积运算通常会被计算机映射成矩阵运算,大规模的矩阵运算不仅对传统冯诺依曼架构的算力提出了较高要求,其带来的大量数据搬移也严重影响着整个系统功耗和速度。特别是在边缘计算领域,物联网设备虽有ai赋能,但其小体量下的电源和算力不足以支撑起大规模计算,大量的功能只能通过将计算数据发送到云端,云端服务器处理完成后传回数据来实现。这种计算方式的延时较高,很难满足如智能汽车这种需要实时处理数据的领域的需求。
4.sram存内计算电路作为目前针对数据密集型应用的热门解决办法,在存储单元内部进行乘法运算,虽然提高了速度,但额外的计算单元也会带来较大面积增加,对边缘计算设备芯片的面积开销提出了挑战。通过控制sram存储电路的数据进行多行复用计算能够有效解决这一挑战,同时也能将更多的数据存于本地,进一步减少数据搬移从而减少系统的功耗。
技术实现要素:
5.针对目前sram存内计算电路面积开销较大、存储密度低的问题,本发明提出了一种基于可复用booth乘法单元的存内计算电路,通过单元和结构上的创新设计在提升存储密度的情况下实现可与读写操作同时进行的存内计算功能。
6.本发明的技术方案是:
7.一种基于可复用booth乘法单元的存内计算电路,所述存内计算电路包括可复用booth乘法单元,加法器树和灵敏放大器。每个可复用booth乘法单元包括sram存储阵列、booth编码器、booth译码器和积产生电路。
8.所述存储阵列,每一行的8管sram(8t-sram)存储单元连接有wl、sl两根信号线,其中wl信号线是读写操作字线,用于在写入和读出操作时选中特定行,sl信号线是存内计算选择线,用于在存内计算模式时选中特定行中的数据送入局部计算数据线。每一列的存储单元连接有bl、blb两根信号线,bl和blb信号线是读写操作位线,用于在写入和读出操作时对每一个sram加载数据。此外,每8行的同一列存储单元连接有lcl和lclb两根信号线,lcl和lclb信号线是存内计算模式的局部计算数据线,用于将选中的sram中的数据采出进行booth乘法编码。
9.所述存内计算电路具有sram模式、存内计算模式和混合模式:sram模式下使用灵敏放大器输出,bl和blb信号线作为灵敏放大器的差分输入;而存内计算模式下首先将所选中行sram的数据进行booth乘法编码,再通过booth译码器对所产生的编码和输入进行译码生成部分积pp,然后通过积产生电路将多个部分积合成乘法结果pout,最后通过加法器树将8个乘法结果累加产生最终的输出out;混合模式即sram模式和存内计算模式同时激活,但需要通过wl和sl信号线的控制保证同一行的存储单元不会同时处于sram模式和存内计算模式,此模式下可以在存内计算的同时进行存储数据的读出或写入。
10.具体的,所述存内计算电路包含8个可复用booth乘法单元和一个加法器树,每个可复用booth乘法单元包括1个8行8列的存储阵列、1个booth编码器、4个booth译码器和1个积产生电路,存内计算模式下存储阵列的每个输出信号线lclb通过一个反相器连接到booth编码器对应的输入信号线cl,同理每一个lcl线也通过相同的反相器连接到对应的clb。加法器树共有8个16位的输入端口,1个19位的输出端口out,每个输入端口对应1个可复用booth乘法单元的输出结果pout。
11.具体的,存储阵列中的sram为8管存储单元,包括第一pmos管、第二pmos管、第一nmos管、第二nmos管、第三nmos管、第四nmos管、第五nmos管、第六nmos管,其中第一pmos管的源极和第二pmos管的源极接电源,第一pmos管的漏极接第二pmos管的栅极、第一nmos管的漏极、第二nmos管的栅极、第三nmos管的漏极和第五nmos管的源极;第二pmos管的漏极接第一pmos管的栅极、第一nmos管的栅极、第二nmos管的漏极、第四nmos管的漏极和第六nmos管的源极;第一nmos管的源极和第二nmos管的源极接地;所有pmos管的衬底接电源,所有nmos管的衬底接地;第三nmos管的栅极接读写操作字线wl,其源极接读写操作位线bl;第四nmos管的栅极接读写操作字线wl,其源极接读写操作位线反blb;第五nmos管的栅极接存内计算选择线sl,其漏极接存内计算模式的局部计算数据线lcl;第六nmos管的栅极接存内计算选择线sl,其漏极接存内计算模式的局部计算数据线反lclb。
12.具体的,booth编码器采用基-4booth编码,1个booth编码器包括4个编码单元(encoder),从高位到低位其输入分别对应cl和clb的高位到低位,特别的,encoder0的最低位输入为固定的0和1。每个编码单元对连续3个存储单元中的值进行编码,产生4个控制信号neg、sf、zero、cor,其中neg和sf同时有反向输出以便于译码。对于一行8个存储单元中存储的8位数据,最终会产生4组4位的控制信号。
13.具体的,每一个booth译码器包括9个译码单元(decoder),从低位到高位每个decoder对应一个输入数据位,需要注意的是第7个和第8个译码单元的输入都是8位输入数据的最高位数据in《7》。同一个booth译码器的9个decoder对应于上述一个encoder的控制信号,例如第0个booth译码器根据encoder0的控制信号和输入in0产生部分积pp0。booth编码器能够根据存储单元中的8位数据和输入的8位数据生成9位的部分积。
14.具体的,积产生电路包括若干半加器和全加器,其具体电路结构本发明不做要求,只对其电路功能进行描述,积产生电路的输入是4个booth译码器生成的4个9位部分积pp3、pp2、pp1、pp0和对应的补偿信号cor《3:0》,根据部分积所处的位对其进行移位相加,如pp1需要在pp0的基础上移2位。最终实现存储阵列中的8位数据和输入8位数据的乘法运算,该乘法运算支持的数据类型为有符号数,所有数据均采用补码表示。
15.具体的,加法器树共包括3级加法器,第1级由4个16比特加法器构成,其输入为8个
可复用booth乘法单元的乘法结果pout0~pout7,产生4个17比特的输出,累加组合方式为单元0-7,相邻两个输入依次结合;第2级由2个17比特加法器构成,产生2个18比特的累加和,累加组合方式和第一级同理;第3级采用1个18比特的加法器,产生1个19比特的累加和作为最终的输出。
16.本发明的有益效果为:本发明通过修改sram基本存储单元,添加booth编码器、booth译码器和积产生电路构成可复用booth乘法单元,实现基本的乘法运算,再添加加法器树实现乘法累加运算;通过控制局部计算数据线的输入,实现存储单元对乘法单元的复用,同时也实现了存储阵列读写操作和存内计算操作的灵活控制。具有存储密度大、灵活性高的特点,适用需要大规模矩阵运算的数据密集型应用,如神经网络。
附图说明
17.图1为本发明提出的一种基于可复用booth乘法单元的存内计算电路示意图。
18.图2为8t-sram存储单元结构示意图。
19.图3为booth编码器结构示意图。
20.图4为booth译码器结构示意图。
具体实施方式
21.下面结合附图对本发明进行详细的描述。
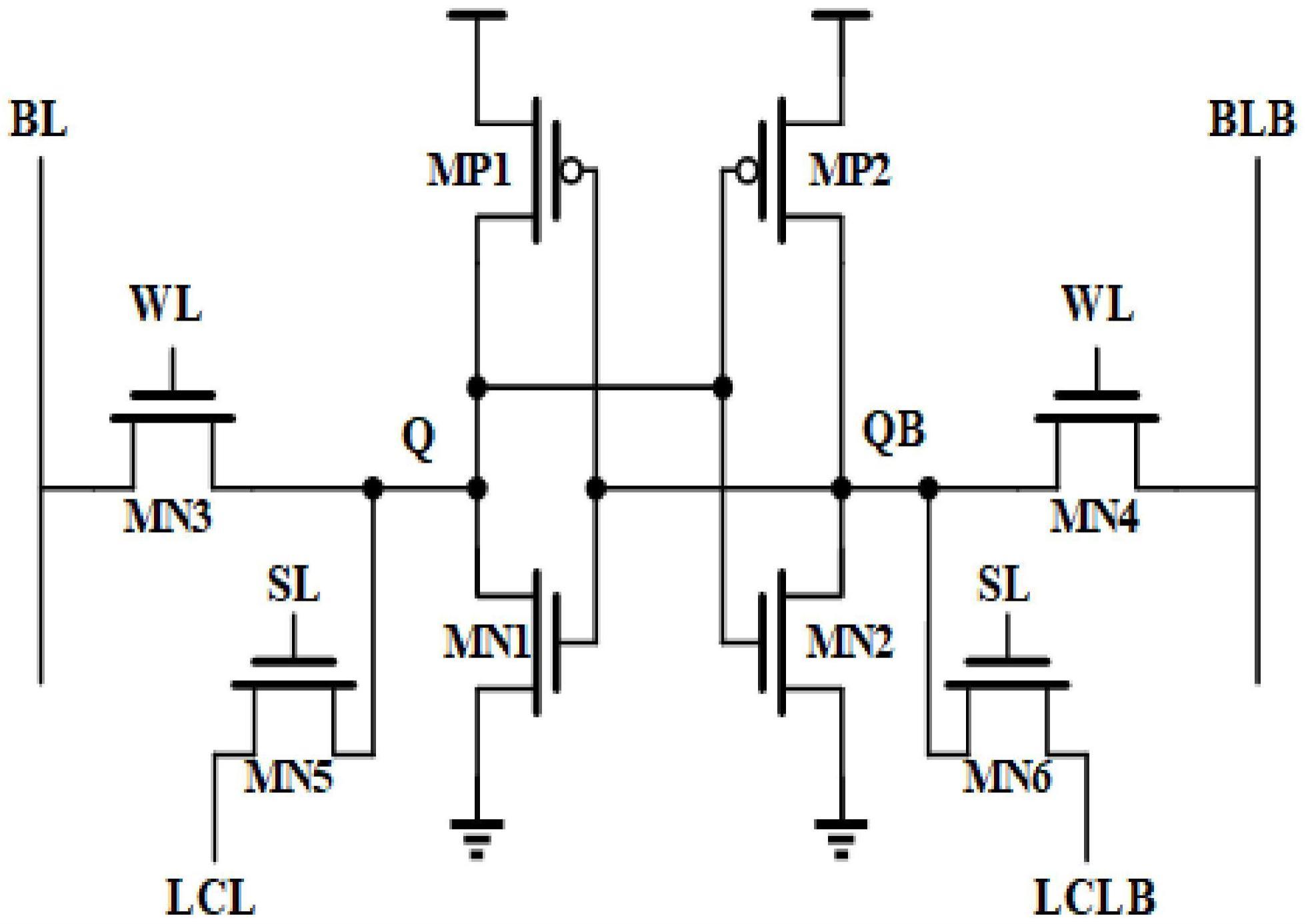
22.图1为本发明提出的一种基于可复用booth乘法单元的存内计算电路示意图。该电路包括8个可复用booth乘法单元,每一个可复用booth乘法单元包括1个8行8列的sram存储阵列、1个booth编码器、4个booth译码器和1个积产生电路,存储阵列的每一行共享wl、sl两根控制信号线,每一列共享bl、blb两根位线和lcl、lclb两根局部计算数据线,位线和灵敏放大器的输入端直接相连,计算数据线和反相器连接后再和booth编码器的输入端相连。每一个可复用booth乘法单元对应一个8比特的输入数据in《7:0》和16比特的乘法结果输出put《15:0》,需要注意的是不同的可复用booth乘法单元有一组相同的控制信号sl《7:0》,即sl《0》为高电平时所有的可复用booth乘法单元都会选中其第0行的存储单元进行存内计算。不同的可复用booth乘法单元之间互相独立,只有同一列sram的bl和blb两根位线对应连接以实现传统的sram存储阵列的读写功能。
23.图2为8t-sram存储单元结构示意图。其中第一、第二pmos源级接电源。第一、第二nmos源级接地。第一pmos的漏极与第二pmos的栅极,第一nmos的漏极,第二nmos的栅极,第三nmos的漏极,第五nmos的源极连接(记为节点q)。第一pmos的栅极与第二pmos的漏极,第一nmos的栅极,第二nmos的漏极,第四nmos的漏极,第六nmos的源极连接(记为节点qb)。第三、第四nmos的栅极连接字线wl。第三nmos的源级连接bl,第四nmos的源级连接blb。第五、第六nmos的栅极连接sl,第五、第六nmos的漏极分别连接lcl和lclb。
24.本发明提出的一种基于可复用booth乘法单元的存内计算电路中所有nmos管的衬底端均与地gnd相连,所有pmos管的衬底端均与电源vdd相连。
25.为了实现存储单元对乘法计算单元的复用,本发明在传统6t-sram的基础上增加两个nmos导通控制管(即第五、第六nmos管),同一列的每8行存储单元连接到对应的lcl和lclb,通过sl信号控制每个周期选择一行的数据采出。由于读写操作和计算操作有分别对
应的导通控制管,能对未处于计算操作下的一行存储单元进行读写操作,从而实现了存储阵列读写操作和存内计算操作的灵活控制。
26.为了实现高效的乘法运算,本发明采用基-4booth乘法减少部分积的数量。利用booth编码器对一行的8个存储单元中的数据进行编码,再根据编码结果和输入数据进行译码产生4个部分积,最后利用积产生电路将4个部分积合成为最后的乘法结果。具体的编码和译码原理将在后续详细说明。
27.为了实现多数据的乘法累加运算,本发明利用加法器树将8个可复用booth乘法单元的乘法结果并行累加。若要实现更多组数据的累加运算,可以在本发明的基础上增加额外的累加电路。
28.下面结合图1、图2、图3和图4具体说明本发明电路的工作原理:
29.1、sram模式:
30.(1)保持操作:
31.在存储单元保持数据期间,字线wl保持低电平。此时第三nmos管mn3和第四nmos管mn4均关断,此时位线bl和blb均不会对存储节点q或qb造成影响。第一pmos管mp1、第二pmos管mp2、第一nmos管mn1以及第二nmos管mn2构成的锁存结构将锁存存储节点q和qb的数据。
32.(2)写操作:
33.假设在写操作前8管存储单元存储节点q为低电平,qb为高电平,即存储数据为
‘0’
。在写入数据
‘1’
时,写操作字线wl被拉高为高电平选中单元,同时将需要写入的数据
‘1’
加载到写位线上,即bl为高电平,blb为低电平。bl通过第三nmos管mn3上拉节点q,blb通过第四nmos管mn4下拉节点qb,锁存结构反馈环被打破,数据
‘1’
被写入存储单元。写入数据
‘0’
与上述过程同理。
34.(3)读操作
35.假设在读操作前存储单元存储节点q为低电平,qb为高电平,即存储数据为
‘0’
。在读操作开始时,位线bl与blb先预充电至高电平,字线wl再被拉高为高电平,第三nmos管mn3和第四nmos管mn4导通,第一nmos管因qb点为高电平而导通。此时bl会通过第一nmos管mn2和第三nmos管被拉低,blb保持不变,完成读取“0”。读出数据“1”与上述过程同理。bl和blb中的电压变化通过与之相连的灵敏放大器放大,最终完成数据的读出。
36.在sram模式下,无论保持操作、写操作还是读操作,sl控制信号线均为低电平,第五nmos管和第六nmos管均关断。若整个电路所有存储单元均处于sram模式,则认为存内计算电路处于sram模式。
37.2、存内计算模式:
38.(1)数据选择
39.存储单元中存储的数据为
‘0’
,即q节点为
‘0’
,qb节点为
‘1’
,计算时代表的就是
‘0’
,存储数据为
‘1’
时同理。在存内计算模式下字线wl保持低电平,第三nmos管和第四nmos管均关断。若整个电路所有存储单元均没有处于sram模式,则认为存内计算电路处于存内计算模式。
40.对于一个可复用booth乘法单元,若要选择第0行的数据和输入相乘,则sl《0》被拉高为高电平,sl《7:1》保持低电平,此时第0行8个sram中的第五nmos管和第六nmos管导通,其余7行的sram的第五、第六nmos管均关断,局部计算数据线lcl和lclb分别采集到对应列
sram的q和qb节点的值。lcl和lclb经过一个反相器后分别和对应booth编码器的输入clb和cl线连接。8个可复用booth乘法单元的数据选择保持同步,即一个周期都会选择其中相同行的数据。
41.(2)booth编码
42.图3为booth编码器结构示意图,包含4个编码单元,encoder3的输入是cl和clb的最高三位,其编码输出也是对应控制信号的最高位,根据编码单元的序号依次递减。对于encoder0,其最低位输入是0和1而与cl和clb无关,这是8比特数据采用基-4booth编码必须的扩展操作。每个编码单元采用标准cmos逻辑,由于具有cl和clb的差分输入,2个异或门节省了2个反相器。具体的编码规则真值表如表1所示。
43.表1booth编码规则真值表
44.根据表1和图3,译码逻辑可以总结为:
45.negi=cl
2i 1
[0046][0047][0048][0049]
(3)booth译码
[0050]
图4为booth译码器结构示意图,每个booth译码器包含9个译码单元,受到同一个booth编码器生成的编码结果控制,第8个译码单元用于移位操作(
±
2x)的扩展,所以和第7个译码单元的输入都是输入数据的最高位in《7》,其他译码单元的输入分别和输出按位对应。由于译码单元的总数量明显多于编码单元,为了降低面积和功耗,译码单元中的异或门和数据选择器没有采用标准cmos逻辑而是传输门逻辑。相邻的译码单元之间ny和nyn互相连接,通过两个传输门进行是否移位的数据选择。输出端zero信号通过或非门控制输出,能够提升0x情况的译码速度。根据图4译码逻辑可以总结为:
[0051][0052]
nynij=nyi
j-1
[0053][0054]
(4)乘法累加
[0055]
积产生电路负责将4个部分积结果pp0、pp1、pp2、pp3和对应的补偿信号cor《0》、cor《1》、cor《2》、cor《3》按对应位相加完成存储单元中的8位数据和输入8位数据的乘法运算,生成乘法结果pout。
[0056][0057]
加法器树负责将同一个周期内8个可复用booth乘法单元的乘法输出结果累加生成最终的乘法累加结果out。
[0058][0059]
上式中,ini表示第i个可复用booth乘法单元的输入数据,wi代表第i个可复用booth乘法单元所选中存储单元的数据。即在一个周期内完成了8个8比特输入和8比特权重的乘法累加运算,通过拼接更多列可以实现矩阵向量乘法运算,通过多个周期累加,可以完成更大规模的矩阵乘法运算。
[0060]
3、混合模式:
[0061]
上文的sram模式和存内计算模式是针对具体某一行的存储单元而定义的,混合模式指的是整个电路既有处于sram模式的部分也有处于存内计算模式的部分,即只要不是所有存储单元都处于sram模式或存内计算模式,电路就处于混合模式。对于某一个sram单元而言sl和wl信号不会同时为高电平,这样才能保证读写操作和存内计算操作的稳定性。由于8行存储单元复用1个计算单元,对于未被选中进行存内计算的存储单元行,可以对其进行正常的读写操作而不会影响正在存内计算操作的单元,这样从整个电路角度看可以在进行存内计算操作的同时对存储单元内的数据进行读写,大大提高了系统的灵活性。
[0062]
综上所述,本发明提出的一种基于可复用booth乘法单元的存内计算电路,通过改进存储单元和整体结构实现了矩阵向量乘法运算。与传统结构相比,本发明通过对存储单元中的数据booth编码,在存储阵列周围完成booth乘法运算,再通过加法器树完成乘法累加运算,减少了数据搬移。与现有存内计算结构相比,通过多行存储单元复用计算单元,提升了电路的存储密度,同时实现了电路级别的读写操作和存内计算操作的并行,提升了电路的灵活性。
当前第1页1
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!