语音情感变化识别方法、装置、电子设备及介质与流程-j9九游会真人
1.本公开涉及自然语言处理领域,特别是涉及一种语音情感变化识别方法、装置、电子设备及介质。
背景技术:
2.自然语言处理中经常需要识别语音情感,例如开心、伤心、愤怒等。现有技术中识别语音情感,一般是从语音片段中提取语音特征,如lfpc(对数频率能量系数)、mfcc(梅尔倒谱系数)特征等,然后利用这些语音特征进行语音情感分类。但是,人的语音中某句的情感会依赖于上下文情感。例如,从上一句过渡到下一句时,如果上一句声音比较小或语速比较慢,下一句声音变大或语速变急促,往往是从无情感变为生气的情感。然而从单条语音来看,声音大和语速急促不一定是生气的情感,有可能是这条语音的说话人本身说话声音比较大,语速比较快。
3.虽然现有技术也出现了结合上下文进行情感识别的方案,但主要依赖情感交互矩阵,需要大量的情感标注数据,效率低下。
技术实现要素:
4.本公开实施例提供了一种语音情感变化识别方法、装置、电子设备及介质,它能高效地识别出语音情感的变化。
5.根据本公开的一方面,提供了一种语音情感变化识别方法,包括:
6.获取第一语音片段和第二语音片段,所述第一语音片段和第二语音片段来自于同一语音段,且所述第一语音片段在所述第二语音片段之前;
7.将所述第一语音片段输入第一模型,生成第一向量,并将所述第二语音片段输入第二模型,生成第二向量,其中,所述第一模型和第二模型具有同样的结构和参数;
8.将所述第一向量和所述第二向量输入分类器,由所述分类器对所述第一语音片段到所述第二语音片段的情感变化进行分类。
9.根据本公开的一方面,提供了一种语音情感变化识别装置,包括:
10.第一获取单元,用于获取第一语音片段和第二语音片段,所述第一语音片段和第二语音片段来自于同一语音段,且所述第一语音片段在所述第二语音片段之前;
11.第一生成单元,用于将所述第一语音片段输入第一模型,生成第一向量,并将所述第二语音片段输入第二模型,生成第二向量,其中,所述第一模型和第二模型具有同样的结构和参数;
12.分类单元,用于将所述第一向量和所述第二向量输入分类器,由所述分类器对所述第一语音片段到所述第二语音片段的情感变化进行分类。
13.可选地,所述第一语音片段到所述第二语音片段的情感变化包括情感状态之间的跃迁,所述情感状态包括有情感和无情感;
14.所述语音情感变化识别装置还包括:第一训练单元,用于通过以下过程联合训练
所述第一模型、所述第二模型和所述分类器:
15.构建第一样本集,所述第一样本集中的第一样本包括第一样本语音片段和第二样本语音片段,所述第一样本具有第一样本标签,用于指示所述第一样本语音片段到所述第二样本语音片段情感状态之间的跃迁;
16.将所述第一样本语音片段输入所述第一模型,生成第一样本向量,并将所述第二样本语音片段输入所述第二模型,生成第二样本向量;
17.将所述第一样本向量和所述第二样本向量输入所述分类器;
18.基于所述分类器的分类结果与所述第一样本标签的比较,构造第一误差函数,并基于所述第一误差函数调整所述第一模型、所述第二模型和所述分类器的参数。
19.可选地,所述语音情感变化识别装置还包括:
20.第二获取单元,用于如果分类出的情感变化为跃迁到有情感,获取所述第二语音片段的词向量序列;
21.第一输入单元,用于将所述词向量序列输入语义编码模型,得到所述第二语音片段的语义向量;
22.第二输入单元,用于将所述词向量序列和所述语义向量输入情感分类模型,得到所述第二语音片段的情感类别。
23.可选地,所述第一语音片段到所述第二语音片段的情感变化包括所述第一语音片段的情感类别和所述第二语音片段的情感类别;
24.所述语音情感变化识别装置还包括:第二训练单元,用于通过以下过程联合训练所述第一模型、所述第二模型和所述分类器:
25.构建第二样本集,所述第二样本集中的第二样本包括第三样本语音片段和第四样本语音片段,所述第二样本具有第二样本标签,用于指示所述第三样本语音片段的情感类别和所述第四样本语音片段的情感类别;
26.将所述第三样本语音片段输入所述第一模型,生成第三样本向量,并将所述第四样本语音片段输入所述第二模型,生成第四样本向量;
27.将所述第三样本向量和所述第四样本向量输入所述分类器;
28.基于所述分类器的分类结果与所述第二样本标签的比较,构造第二误差函数,并基于所述第二误差函数调整所述第一模型、所述第二模型和所述分类器的参数。
29.可选地,所述语音情感变化识别装置还包括:
30.第三输入单元,用于将所述第一向量和所述第二向量输入说话者判决器,由所述说话者判决器判定所述第一语音片段的发出者和第二语音片段的发出者是否相同;
31.第三训练单元,用于通过以下过程联合训练所述第一模型、所述第二模型、所述分类器和所述说话者判决器:
32.构建第三样本集,所述第三样本集中的第三样本包括第五样本语音片段和第六样本语音片段,所述第三样本具有第三样本标签和第四样本标签,所述第三样本标签用于指示所述第五样本语音片段到所述第六样本语音片段的情感变化,所述第四样本标签用于指示所述第五样本语音片段的发出者和所述第六样本语音片段的发出者是否相同;
33.将所述第五样本语音片段输入所述第一模型,生成第五样本向量,并将所述第六样本语音片段输入所述第二模型,生成第六样本向量;
34.将所述第五样本向量和所述第六样本向量输入所述分类器,并将所述第五样本向量和所述第六样本向量输入所述说话者判决器;
35.基于所述分类器的分类结果与所述第三样本标签的比较、所述说话者判决器的判定结果与所述第四样本标签的比较,构造第三误差函数,并基于所述第三误差函数调整所述第一模型、所述第二模型、所述分类器和所述说话者判决器的参数。
36.可选地,所述第三训练单元具体用于:
37.基于所述分类器的分类结果与所述第三样本标签的比较,构造第一误差子函数;
38.基于所述说话者判决器的判定结果与所述第四样本标签的比较,构造第二误差子函数;
39.基于所述第一误差子函数与所述第二误差子函数,构造所述第三误差函数。
40.可选地,所述第三训练单元具体用于:
41.针对所述第三样本集中的第三样本,构造第一键,其中,所述第一键为第一值时指示所述分类器的分类结果与所述第三样本标签相同,所述第一键为第二值时指示所述分类器的分类结果与所述第三样本标签不同;
42.获取所述分类器对所述分类结果的第一预测概率;
43.基于所述第一键和所述第一预测概率,构造所述第一误差子函数。
44.可选地,所述第三训练单元具体用于:
45.针对所述第三样本集中的第三样本,构造第二键,其中,所述第二键为第一值时指示所述说话者判决器的判定结果与所述第四样本标签相同,所述第二键为第二值时指示所述说话者判决器的判定结果与所述第四样本标签不同;
46.获取所述说话者判决器对所述判定结果的第二预测概率;
47.基于所述第二键和所述第二预测概率,构造所述第二误差子函数。
48.可选地,所述第一获取单元具体用于:
49.对所述第一语音片段和所述第二语音片段所在的语音段进行语音识别,得到文本段;
50.在所述文本段中选取第一子文本段和第二子文本段,所述第一子文本段在所述第二子文本段之前;
51.根据所述第一子文本段中语句的注意力分数,在所述第一子文本段中选取第一语句,根据所述第二子文本段中语句的注意力分数,在所述第二子文本段中选取第二语句;
52.从所述语音段中获取所述第一语句对应的语音片段作为第一语音片段,获取所述第二语句对应的语音片段作为第二语音片段。
53.可选地,所述语音情感变化识别装置还包括:
54.提取单元,用于从所述第一语音片段中提取第一情感特征序列,从所述第二语音片段中提取第二情感特征序列;
55.合并单元,用于将所述第一情感特征序列并入所述第一向量,将所述第二情感特征序列并入所述第二向量。
56.可选地,所述语音情感变化识别装置还包括:
57.第三获取单元,用于获取第三语音片段,所述第三语音片段与所述第二语音片段来自于同一语音段,且在所述第二语音片段之后;
58.第二生成单元,用于将所述第三语音片段输入第三模型,生成第三向量,其中,所述第三模型与所述第二模型具有同样的结构和参数;
59.所述分类单元具体用于:将所述第一向量、所述第二向量和所述第三向量输入分类器,由所述分类器对所述第一语音片段到所述第二语音片段的情感变化进行分类,并对所述第二语音片段到所述第三语音片段的情感变化进行分类。
60.可选地,所述语音情感变化识别装置还包括:
61.确定单元,用于根据所述分类器的情感变化分类结果,确定对所述情感变化分类结果的响应;
62.执行单元,用于执行所述响应。
63.根据本公开的一方面,提供了一种电子设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现如上所述的语音情感变化识别方法。
64.根据本公开的一方面,提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的语音情感变化识别方法。
65.根据本公开的一方面,提供了一种计算机程序产品,该计算机程序产品包括计算机程序,所述计算机程序被计算机设备的处理器读取并执行,使得该计算机设备执行如上所述的语音情感变化识别方法。
66.本公开实施例不是根据单独的语音片段识别情感,而是从时间上有先后关系的第一语音片段和第二语音片段中识别语音情感的变化,识别过程体现了语音的上下文,提高了识别的准确性。同时,它将第一语音片段输入第一模型,生成第一向量,并将第二语音片段输入第二模型,生成第二向量,而所述第一模型和第二模型具有同样的结构和参数,同样的结构和参数保证了第一向量和第二向量能够忠实体现第一语音片段和第二语音片段的固有性质,将这样得到的第一向量和第二向量输入分类器,能够得到准确的情感变化识别结果。整个过程不依赖情感交互矩阵,不需要大量的情感标注数据,能高效地识别出语音情感的变化。
67.本公开的其他特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本公开而了解。本公开的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
附图说明
68.附图用来提供对本公开技术方案的进一步理解,并且构成说明书的一部分,与本公开的实施例一起用于解释本公开的技术方案,并不构成对本公开技术方案的限制。
69.图1是根据本公开的实施例的语音情感变化识别方法应用的系统的体系构架图;
70.图2a-b是根据本公开的实施例的语音情感变化识别方法应用在贴身情绪管家场景下的界面图;
71.图3a-b是根据本公开的实施例的语音情感变化识别方法应用在智能驾驶场景下的示意图;
72.图4是根据本公开的实施例的语音情感变化识别方法应用在家庭影院场景下的示意图;
73.图5a-b是根据本公开的实施例的语音情感变化识别方法应用在家庭防盗报警场景下的示意图;
74.图6是根据本公开的一个实施例的语音情感变化识别方法的流程图;
75.图7a-e是图6的步骤610的5个具体实施例的示意图;
76.图8示出了实施图7e的实施例的一种具体结构;
77.图9示出了实施根据本公开的一个实施例的语音情感变化识别方法的一种具体结构;
78.图10a示出了图9的第一模型或第二模型的层级概图,图10b示出了图9的第一模型或第二模型的层级结构图;
79.图11a-b示出了图9的分类器的两种具体结构;
80.图12示出了实施根据本公开的一个实施例的语音情感变化识别方法的另一种具体结构;
81.图13示出了图12的语义编码模型的一种具体结构;
82.图14示出了图12的情感分类模型的一种具体结构;
83.图15示出了实施根据本公开的一个实施例的语音情感变化识别方法的另一种具体结构;
84.图16示出了图15的说话者判决器的一种具体结构;
85.图17示出了联合训练图9的第一模型、第二模型和分类器的一种实施方式的流程图;
86.图18示出了联合训练图9的第一模型、第二模型和分类器的另一种实施方式的流程图;
87.图19示出了联合训练图15的第一模型、第二模型、分类器和说话者判决器的一种实施方式的流程图;
88.图20示出了图19的步骤1940的一种具体流程图;
89.图21是根据本公开的另一个实施例的语音情感变化识别方法的流程图;
90.图22示出了实施根据本公开的一个实施例的语音情感变化识别方法的另一种具体结构;
91.图23示出了实施根据本公开的一个实施例的语音情感变化识别方法的另一种具体结构;
92.图24是根据本公开的另一个实施例的语音情感变化识别方法的流程图;
93.图25是本公开实施例基于识别出的语音情感变化执行响应的示意图;
94.图26是根据本公开的实施例的语音情感变化识别方法应用在贴身情绪管家场景下的模块构架图;
95.图27是根据本公开的实施例的语音情感变化识别方法应用在智能驾驶场景下的模块构架图;
96.图28是根据本公开的实施例的语音情感变化识别方法应用在家庭影院场景下的模块构架图;
97.图29是根据本公开的实施例的语音情感变化识别方法应用在家庭防盗报警场景下的模块构架图;
98.图30示出了根据本公开的实施例的语音情感变化识别方法识别语音情感变化的实验结果数据;
99.图31是根据本公开的一个实施例的语音情感变化识别装置的框图;
100.图32是实施根据本公开的一个实施例的语音情感变化识别方法的终端结构图;
101.图33是实施根据本公开的一个实施例的语音情感变化识别方法的服务器结构图。
具体实施方式
102.为了使本公开的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本公开进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本公开,并不用于限定本公开。
103.对本公开实施例进行进一步详细说明之前,对本公开实施例中涉及的名词和术语进行说明,本公开实施例中涉及的名词和术语适用于如下的解释:
104.人工智能:是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得目标结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。随着人工智能技术研究和进步,人工智能技术在多个领域展开研究和应用,例如常见的智能家居、智能穿戴设备、虚拟助理、智能音箱、智能营销、无人驾驶、自动驾驶、无人机、机器人、智能医疗、智能客服等,相信随着技术的发展,人工智能技术将在更多的领域得到应用,并发挥越来越重要的价值。
105.自然语言处理:是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。自然语言处理主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文ocr等方面。
106.情感分类:是指对语料中段、语句、词等要素体现出的情感的类型进行识别。在一种情感分类中,仅需要识别情感的正负倾向,即正面情感还是负面情感。在另一种情感分类中,需要识别具体的情感,如平静、悲伤、愤怒、高兴等。它可以广泛用于互联网上评论的情感识别、人机对话中根据说话人情感调整应答方式、互联网素材的打标签和生成摘要等。
107.域对抗:迁移学习的一个重要分支,用于消除不同域之间的特征分布差异。它把具有不同分布的源域和目标域的数据,映射到同一个特征空间中,并寻找某种度量准则,使得源域上分为同一类的样本的距离尽可能近。这样,在源域上训练好的分类器,可以直接用于
目标域数据的分类。
108.自然语言处理中经常需要识别语音情感,例如开心、伤心、愤怒等。现有技术中识别语音情感,一般是从语音片段中提取语音特征,如lfpc(对数频率能量系数)、mfcc(梅尔倒谱系数)特征等,然后利用这些语音特征进行语音情感分类。但是,人的语音中某句的情感会依赖于上下文情感。例如,从上一句过渡到下一句时,如果上一句声音比较小或语速比较慢,下一句声音变大或语速变急促,往往是从无情感变为生气的情感。然而从单条语音来看,声音大和语速急促不一定是生气的情感,有可能是这条语音的说话人本身说话声音比较大,语速比较快。
109.现有的结合上下文进行情感识别的方案主要依赖情感交互矩阵,需要大量的情感标注数据,效率低下。因此,需要一种高效地识别出语音情感的变化的技术。
110.本公开实施例应用的系统体系构架及场景说明
111.图1是根据本公开的实施例的语音情感变化识别方法所应用的系统构架图。它包括终端140、互联网130、网关120、服务器110等。
112.终端140是接收对象的语音、从语音中识别出对象的情感变化并进行相应处理的设备。它包括桌面电脑、膝上型电脑、pda(个人数字助理)、手机、车载终端、家庭影院终端、专用终端等多种形式。随着本公开实施例在如后文所述的贴身情绪管家、智能驾驶、家庭影院和家庭防盗报警等场景的应用,它可以具体体现为手机、车载终端、家庭影院终端、防盗报警专用终端等形式。另外,它可以是单台设备,也可以是多台设备组成的集合。终端140可以以有线或无线的方式与互联网130进行通信,交换数据。
113.服务器110是指能对终端140提供某些服务的计算机系统。相对于普通终端140来说,服务器110在稳定性、安全性、性能等方面都要求更高。服务器110可以是网络平台中的一台高性能计算机、多台高性能计算机的集群、一台高性能计算机中划出的一部分(例如虚拟机)、多台高性能计算机中划出的一部分(例如虚拟机)的组合等。服务器110在某些应用场景下(如后文提到的智能驾驶、家庭防盗报警等),能够对终端140识别出情感变化后执行相关相应提供支持(例如识别出司机的情感急剧变化是由于发生紧急路况时通知管理中心远程操作、识别出家中成员的情感急剧变化是由于家中闯入坏人时通知家中在外成员等)。
114.网关120又称网间连接器、协议转换器。网关在传输层上实现网络互连,是一种充当转换作用的计算机系统或设备。在使用不同的通信协议、数据格式或语言,甚至体系结构完全不同的两种系统之间,网关是一个翻译器。同时,网关也可以提供过滤和安全功能。终端140向服务器110发送的消息要通过网关120发送到相应的服务器110。服务器110向终端140发送的消息也要通过网关120发送到相应的终端140。
115.本公开实施例可以应用在多种场景下,如图2a-b所示的贴身情绪管家的场景、图3a-b所示的智能驾驶的场景、图4所示的家庭影院的场景、图5a-b所示的家庭防盗报警的场景等。
116.(一)贴身情绪管家的场景
117.目前,人工智能已经迅速渗透到人们生产、生活的各个角落。人们不仅期望通过人工智能来执行生产、生活中需要完成的任务,还期望在执行任务之外其能够提供各种增值服务。目前,智能终端缺乏对对象的情绪进行实时管理的功能。例如,当对象伤心时,能够实时进行安慰或播放欢快的歌曲。当对象愤怒时,能够对对象的愤怒进行平复等。本公开实施
例提出一种贴身情绪管家的功能。它可以作为一种应用(app)安装到对象的终端140(如手机等)中,其实时通过收音器收集对象的语音,当识别出对象的语音中出现情感变化时,采用相应的情绪管理策略管理对象的情绪。
118.如图2a所示,当终端140检测到对象的语音时,这时在终端140的界面上出现了声音的波形,并显示“录音中”的提示。如果根据检测到的对象的语音,识别出对象的情感由“平静”变成了“悲伤”后,这时终端140为了安抚对象的情绪,决定为对象播放大自然音乐以舒缓对象的情绪。此时,如图2b所示,在终端140的界面上显示“识别出您的情感状态:平静到悲伤。将为您播放大自然音乐”。
119.应当注意,终端140并不是只有播放音乐这一种管理对象情绪的方式,还可以采用播放事先录制的语音、控制灯光闪烁等多种方式。例如,当识别出对象的情绪由“平静”变成了“愤怒”后,播放事先录制的语音“冲动是魔鬼。稍安勿燥,不要用别人的错误惩罚自己”等,从而阻止对象冲动行事。另外,在终端140(例如手机)的外壳可以设置有闪烁灯。当识别出对象的情绪由“平静”变成了“愉悦”后,控制闪烁灯闪烁,可以增加对象的愉悦感。
120.(二)智能驾驶的场景
121.在车辆行驶的过程中,可能会发生一些突发路况(例如车辆前方突然闯出一个行人、前方突然出现障碍物),对于不老练的司机,可能会由于紧张产生操作错误,发生交通事故。但是,司机或车上的乘客在遇到突发路况的时候都会本能地叫喊,从而产生人的语音情感变化。如果车辆终端能够识别出司机或乘客情感上的变化,根据情感上的变化自动检测车辆周围环境的变化,从而自动采取一些应对策略(如紧急刹车、并道等),则可以避免一些由于司机过于紧张不会操作导致的交通事故的发生。
122.如图3a所示,车辆正在行驶。车后座上的乘客正在说话:“今天天好蓝啊!”。这时,乘客从车辆的前视窗中看到有一个老人突然从旁边闯到车辆前方,乘客不禁激动地大叫:“有老人,快停车,停车!”这时司机遇到突发状况,手忙脚乱,方向盘失控,也不能即时刹车。车辆终端140识别乘客的语音中的情感变化是由“平静”变“激动”,自动开启摄像头进行周围环境的检测。同时,在图3a的车辆终端显示屏上显示“检测到您的情绪由平静变激动,为您启动周围环境检测”。
123.开启摄像头进行周围环境的检测后,从摄像头拍摄的视频中发现一个老人正闯入车辆前方,于是触发刹车装置急速刹车。这时,即时司机手忙脚乱,仍然可能避免交通事故的发生。此时,如图3b所示,在车辆终端显示屏上显示“检测到前方有行人,为您紧急刹车”。
124.另外,在一些特殊情况下(例如摄像头拍摄的视频显示路况比较复杂,靠简单的刹车或并道无法解决问题,或者车辆开出窄胡同,无法倒出),车辆终端140可能向图1中的服务器110发送求助消息,由服务器110处的管理人员接管远程驾驶。
125.(三)家庭影院的场景
126.对象在家庭影院观影时,随着影片上情节的发展,对象的心境也沉浸与其中,此时对象往往需要拥有更加身临其境的体验。此时,如果整个房间的氛围也能随影片中情节的发展而变化,对象就能够有更加身临其境的体验。例如,当影片中的男女主人公表白时,男女主人公的语音由“平静”变为“甜蜜”,这时如果能控制整个房间的灯光显示朦胧的粉红色,喷雾口喷出淡淡的烟雾,则大大提高了对象的沉浸式体验。
127.如图4所示,家庭影院终端140与房间中的各个灯相连,能够控制各个灯的开/关、
渐强/渐弱、和闪烁。当识别出电影中主人公的说话由“平静”变成“哀伤”后,家庭影院终端140为了配合哀伤的氛围,控制房间中的各个灯逐渐变暗,以使对象更加具有沉浸式的体验。此时,也可以在家庭影院终端140的显示器屏幕上显示“提示:电影画面由平静转为哀伤,将进入黑灯模式”。
128.(四)家庭防盗报警的场景
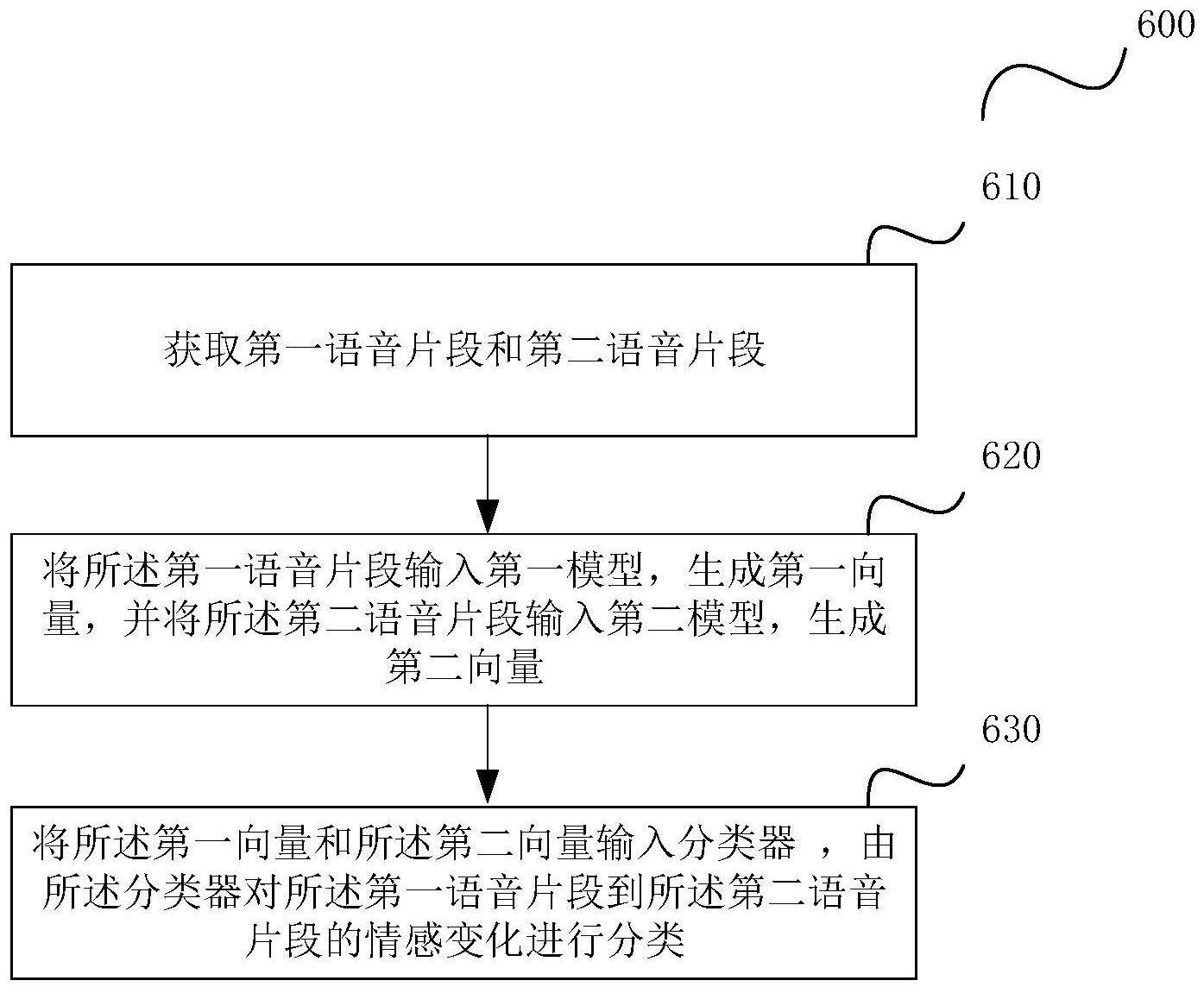
129.本公开实施例的语音情感变化识别方法也可以应用于家庭防盗报警的场景。上班族经常会遇到小孩或老人独自在家的情况。如果家里发生盗窃、火灾、陌生人闯入等情况,上班的人需要第一时间了解,并及时作出处理。虽然很多家庭安装了摄像头,上班的人也可以通过手机远程查看摄像头中拍摄的视频,但上班的人不可能时时查看手机。一旦家里发生了意外,上班的人又漏过了查看手机,能够导致严重后果。因此,需要一种能够在家中发生意外情况时及时通知上班的人查看手机,使得上班的人不用时时盯着家中画面的技术。
130.通过本公开实施例的语音情感变化识别方法可以做到这一点。家中安装专用防盗报警终端140,收集家中的人(老人或小孩等)的语音。当家里发生意外(如闯入了盗贼),家中的人会出于本能地喊叫,此时的情感与家中的人之前说话的情感发生了变化。专用防盗报警终端140从收集的语音中识别出情感变化,触发摄像头拍摄画面,并通过服务器110实时将拍摄的画面传送到上班的人的终端140(如手机),并提醒上班的人查看(例如发出铃响声)。上班的人打开携带的终端140,可以看到家中摄像头拍摄的画面,以便采取应对措施。
131.如图5a所示,家中的小孩躺着床上正与奶奶说着话,这时闯入了一个盗贼。小孩大喊“谁?来人啊,救命”。这时桌上的专用防盗报警终端140根据采集的语音识别出小孩说话的情感由“平静”变为“激动”,此时启动摄像头(未示)进行视频采集,并将采集的视频通过服务器110发送到上班的人的终端140。上班的人的终端140发出铃响声,提醒上班的人查看。上班的人查看终端140。如图5b所示,终端140的显示屏上显示“家里识别到情感变化异常,将为您显示家中实时拍摄画面”。接着,显示家中摄像头拍摄的视频。
132.本公开实施例的总体说明
133.根据本公开的一个实施例,提供了一种语音情感变化识别方法。
134.语音情感是指语音中表现出人的感情,如高兴、生气、悲伤、激动等。它可以是一段语音中表现出的感情,也可以是一句话的语音中表现出的感情,也可以是一个词的语音中表现中的感情,等等,本公开对此不作具体限定。
135.语音情感变化是指语音中时间上在后的部分与时间上在前的部分相比情感发生的变化。它可以是是否有情感的变化,即情感状态的变化,情感状态包括有情感和无情感。在这种情况下,语音情感变化分为四种:无情感
→
有情感、有情感
→
无情感、无情感
→
无情感、有情感
→
有情感。或者,由于有情感
→
有情感较难识别,语音情感变化分为三种:无情感
→
有情感、有情感
→
无情感、无情感
→
无情感。另外,它还可以是具体情感的变化,如平静
→
悲伤、悲伤
→
喜悦、平静
→
激动,等等。
136.语音情感变化识别方法即识别上述语音情感变化的方法。语音情感变化识别方法可以用于辅助语音情感识别、辅助人机对话的应答、以及如上所述的贴身情绪管家、智能驾驶中突发状况的自动紧急处理、家庭影院的体验增强、和家庭防盗报警等中。
137.如图6所示,根据本公开一个实施例的语音情感变化识别方法包括:
138.步骤610、获取第一语音片段和第二语音片段;
139.步骤620、将第一语音片段输入第一模型,生成第一向量,并将第二语音片段输入第二模型,生成第二向量;
140.步骤630、将第一向量和第二向量输入分类器,由分类器对第一语音片段到第二语音片段的情感变化进行分类。
141.下面对步骤610-630进行详细描述。
142.在步骤610中,获取第一语音片段和第二语音片段。这里的第一语音片段和第二语音片段来自于同一语音段,且第一语音片段在第二语音片段之前。
143.语音段是记录的一段语音,它体现为图7a-e所示随时间变化幅度不断变化的语音波形。语音片段是从语音段中截取出的片段,体现为从图7a-e的语音波形中截取的语音波形片段。语音段可以是按照周期记录的语音段,也可以是按照语音触发记录的语音段。
144.按照周期记录是指收音器每隔预定周期就记录该周期内的语音波形,因此,语音段就是这段周期内记录的语音波形。例如,周期为5秒,收音器在这5秒中记录的语音波形就成为一个语音段。按照语音触发是指收音器在没有检测到语音时不记录,一旦检测到语音时开始记录,且当在一段预定时长内检测不到语音后,记录停止。例如,预定时长为5秒。对象只说了一句话。从检测到这句话的开头,收音器开始记录,当这句话说完后,停了5秒,仍然没有说第二句话,则认为这段语音结束,结束记录。如果对象连续说了两句话,从检测到第一句话的开头,收音器开始记录。第一句话和第二句话之间停顿不够5秒,继续记录。当对象说完第二句话后,停了5秒,仍然没有说第三句话,则认为这段语音结束,结束记录。
145.第一语音片段和第二语音片段可以是连续的,如图7b-d所示,也可以不是连续的,如图7a和7e所示。
146.下面结合图7a-e对获取第一语音片段和第二语音片段的不同情形进行描述。
147.在一个实施例中,第一语音片段和第二语音片段可以随机选取,但要保证第一语音片段在第二语音片段之前。由于第一语音片段和第二语音片段是随机选取的,它不能保证第一语音片段和第二语音片段都对应于一个完整的语句或语义。如图7a所示,整个语段对应于对象说出的话“今天天气好晴朗。看!前面有个木桩子,快停车”。选取第一语音片段,该第一语音片段对应于对象说出的“今天天气好晴”。由于“朗”没有在第一语音片段中,因此,第一语音片段表达不了一个完整的语义。选取第二语音片段,该第二语音片段对应于对象说出的“有关木桩子,快停车”。由于“看!前面”没有在第二语音片段中,因此,第二语音片段也表达不了一个完整的语义。虽然第一语音片段和第二语音片段可能表达不了完整的语义,但是前后的情感变化还是在第一语音片段和第二语音片段中有体现,因此,可以这样选取第一语音片段和第二语音片段供后续的情感变化识别使用。
148.在另一个实施例中,将语音段等分为第一语音片段和第二语音片段。第一语音片段和第二语音片段的时间长度相等,且第一语音片段在第二语音片段之前。由于第一语音片段和第二语音片段是等时划分,它们仍然不一定能够代表一个完整的语句或语义。如图7b所示,由于第一语音片段和第二语音片段是按等时长划分,第一语音片段对应于“今天天气好晴朗。看!”的语音,第二语音片段对应于“前面有个木桩子,快停车”的语音。这种情况下,虽然第一语音片段和第二语音片段表达不了完整的语义,但可能仍然能够用于后续的情感变化识别。
149.在另一个实施例中,可以按语句划分第一语音片段和第二语音片段。将语音段利
用语音识别转化成文本段。对文本段进行分句处理,得到文本段中的句子。将文本段中在前的句子对应的语音作为第一语音片段,将文本段中在后的句子对应的语音作为第二语音片段。如图7c所示,将语音段利用语音识别技术,识别成“今天天气好晴朗。看!前面有个木桩子,快停车”这样一个文本段。经过分句处理,分为“今天天气好晴朗。”、“看!前面有个木桩子,快停车”两个句子。将前一个句子对应的语音作为第一语音片段,将后一个句子对应的语音作为第二语音片段。如果从文本段中分出多于二个句子,可以在多于二个句子中任取出两个句子,将前一个句子对应的语音作为第一语音片段,将后一个句子对应的语音作为第二语音片段。该实施例由于考虑到语义的完整性,划分出的第一语音片段和第二语音片段能够提高情感变化识别的准确度。
150.在另一个实施例中,可以按语音停顿划分第一语音片段和第二语音片段。如果语音段中语音停顿超过预定时长,将语音段中该语音停顿之前的部分作为第一语音片段,将语音段中该语音停顿之后的部分作为第二语音片段。这样分出的每个语音片段可能包括多个句子。如图7d所示,假设预定时长为5秒。对象在说出“今天的天真蓝,一朵云彩也没有,今天天气真晴朗”之后,过了6秒,说“咦,前面是个什么东西,我没戴眼镜,看不清楚。天啊,前面有个木桩子,快停车!来不及了,快停!”。这时,将“今天的天真蓝,一朵云彩也没有,今天天气真晴朗”对应的语音识别成第一语音片段,将“咦,前面是个什么东西,我没戴眼镜,看不清楚。天啊,前面有个木桩子,快停车!来不及了,快停!”对应的语音识别成第二语音片段。由于语音停顿前后往往会表达不同的语义,带有不同的情感,因此,这样划分出的第一语音片段和第二语音片段能够提高情感变化识别的准确度。
151.在另一个实施例中,可以引入注意力模型获取第一语音片段和第二语音片段。对象说出的一段话中,每句话并不是同等重要的,而每句话表达出的情感可能是不同的,对象说出的话中最重要的一句话表达的情感可能才是对象最主要的情感。因此,可以利用注意力模型确定出对象说出的前后两段话中各句子的注意力分数,并基于注意力分数来确定将哪个句子对应的语音作为第一语音片段或第二语音片段。如图7e所示,对象先说出“今天的天真蓝,一朵云彩也没有,今天天气真晴朗”之后,过了6秒,说“咦,前面是个什么东西,我没戴眼镜,看不清楚。天啊,前面有个木桩子,快停车!来不及了,快停!”在前一段话中,经注意力模型识别,“今天天气真晴朗”是注意力分数最高的一句。因此,将“今天天气真晴朗”作为第一语音片段。在后一段话中,经注意力模型识别,“前面有个木桩子,快停车!”是注意力分数最高的一句。因此,将“前面有个木桩子,快停车!”作为第二语音片段。由于该实施例利用注意力分数来选取第一语音片段和第二语音片段,而注意力分数代表了各句子的重要程度,因此,提高了第一语音片段和第二语音片段的选取质量,更能提高情感变化识别的准确度。
152.在该实施例具体实现时,步骤610可以包括:
153.获取对第一语音片段和第二语音片段所在的语音段进行语音识别,得到文本段;
154.在文本段中选取第一子文本段和第二子文本段,第一子文本段在第二子文本段之前;
155.根据第一子文本段中语句的注意力分数,在第一子文本段中选取第一语句,根据第二子文本段中语句的注意力分数,在第二子文本段中选取第二语句;
156.从语音段中获取第一语句对应的语音片段作为第一语音片段,获取第二语句对应
的语音片段作为第二语音片段。
157.下面结合图7e和图8对上述过程进行详细描述。
158.文本段即语音段经语音识别而形成的文本,如图7e的“今天的天真蓝,一朵云彩也没有,今天天气真晴朗。咦,前面是个什么东西,我没戴眼镜,看不清楚。天啊,前面有个木桩子,快停车!来不及了,快停!”语音识别可以通过图8的第一语音识别模型810实现。常见的语音识别模型包括动态时间规整(dyanmic time warping)、矢量量化(vector quantization)、隐马尔可夫模型(hidden markov models)等。
159.在文本段中选取第一子文本段和第二子文本段可以通过图8的分段装置820执行。分段装置820从语音段中识别语音停顿。如果语音停顿超过预定时长(如5秒),将语音段中该语音停顿之前的部分识别成的文字作为第一子文本段,将语音段中该语音停顿之后的部分识别成的文字作为第二子文本段。如图7e的例子中,对象在说出“今天的天真蓝,一朵云彩也没有,今天天气真晴朗。”和“咦,前面是个什么东西,我没戴眼镜,看不清楚。天啊,前面有个木桩子,快停车!来不及了,快停!”之间停顿了6秒,超过预定时长5秒,因此,将“今天的天真蓝,一朵云彩也没有,今天天气真晴朗。”作为第一子文本段,将“咦,前面是个什么东西,我没戴眼镜,看不清楚。天啊,前面有个木桩子,快停车!来不及了,快停!”作为第二子文本段。
160.根据第一子文本段中语句的注意力分数,在第一子文本段中选取第一语句,可以通过如图8的第一句向量序列转换模块830、第一注意力模型850、第一判决模块870实现。根据第二子文本段中语句的注意力分数,在第二子文本段中选取第二语句,可以通过如图8的第二句向量序列转换模块840、第二注意力模型860、第二判决模块880实现。
161.注意力模型是指在特定场景下解决某个问题时,对解决该问题需要考虑的不同信息施加不同的权重(注意力分数),对问题帮助大的信息施加更高的权重,对问题帮助小的信息施加更低的权重,从而更好地运用这些信息解决问题的模型。具体到本公开实施例,第一子文本段中具有多个语句,每个语句对于识别对象的情感变化这样一个问题的贡献有大有小。对于识别对象的情感变化贡献大的语句,通过注意力模型赋予更大的注意力分数。对于识别对象的情感变化贡献小的语句,通过注意力模型赋予更小的注意力分数。
162.注意力模型一般是以二进制序列为输入的,而第一子文本段的各语句、第二子文本段的各语句是文本,因此,要通过第一句向量序列转换模块830、第二句向量序列转换模块840转换成相应的句向量。将语句转换成句向量的方法可以是,将语句利用分词技术分词,将分出的词转换成词向量,再将词向量按照词在语句中的顺序拼接,就得到了句向量。将词转换成词向量可以采取独热(one-hot)向量表示法、词嵌入(word embedding)法。词嵌入(word embedding)法可以采用word2vec训练算法。
163.第一句向量序列转化模块830将第一子文本段的每个词转换成相应的句向量,第一子文本段的各个词的句向量合起来形成第一句向量序列。第二句向量序列转化模块840将第二子文本段的每个词转换成相应的句向量,第二子文本段的各个词的句向量合起来形成第二句向量序列。
164.图8示出了第一注意力模型850和第二注意力模型860的典型结构。第一注意力模型850和第二注意力模型860各自包括多个注意力模型节点,并根据接收到的输入句向量的数目决定启用注意力模型节点的数目。假设第一子文本段包括m个语句,对应有m个句向量,
第一注意力模型850启用m个注意力模型节点l1、l2
……
lm,接收m个句向量的输入,其中m为大于等于2的正整数。第二子文本段包括n个语句,对应有n个句向量,第二注意力模型860启用n个注意力模型节点p1、p2
……
pn,接收n个句向量的输入,其中n为大于等于2的正整数。由于每个语句的注意力分数是体现在各语句的上下文关系中的,因此,各注意力模型节点要把本节点的状态向下一个注意力模型节点传递,从而下一个注意力模型节点衡量语句的注意力分数时,不仅考虑该语句的内容,还要考虑上一个注意力模型节点传递的状态。
165.第一注意力模型850根据第一子文本段中各语句的句向量,产生该语句的注意力分数,由第一判决模块870选择注意力分数最高的语句作为第一语句。具体地,如图8所示,注意力模型节点l1、l2
……
lm接收第一子文本段中m个语句的m个句向量作为输入,输出m个语句的注意力分数a1、a2
……
am。然后,第一判决模块870从中挑选出注意力分数最高的语句作为第一语句。例如,对于“今天的天真蓝,一朵云彩也没有,今天天气真晴朗。”这样一个第一子文本段,注意力模型节点l1输出“今天的天真蓝”的注意力分数a1为40,“一朵云彩也没有”的注意力分数a2为50,“今天天气真晴朗”的注意力分数为90,因此,选择注意力分数最高的“今天天气真晴朗”作为第一语句。
166.第二注意力模型860根据第二子文本段中各语句的句向量,产生该语句的注意力分数,由第二判决模块880选择注意力分数最高的语句作为第二语句。具体地,如图8所示,注意力模型节点p1、p2、
……
pn接收第二子文本段中n个语句的n个句向量作为输入,输出n个语句的注意力分数b1、b2
……
bn。然后,第二判决模块880从中挑选出注意力分数最高的语句作为第二语句。例如,对于“咦,前面是个什么东西,我没戴眼镜,看不清楚。天啊,前面有个木桩子,快停车!来不及了,快停!”这样一个第一子文本段,注意力模型节点p1输出“咦,前面是个什么东西”的注意力分数b1为40,“我没戴眼镜,看不清楚”的注意力分数b2为20,“天啊”的注意力分数b3为10,“前面有个木桩子,快停车”的注意力分数b4为80,“来不及了,快停”的注意力分数b5为70,因此,选择注意力分数最高的“前面有个木桩子,快停车”作为第二语句。
167.获得第一语句和第二语句后,第一匹配单元890可以从语音段中截取出第一语句对应的语音片段,作为第一语音片段,第二匹配单元895可以从语音段中截取出第二语句对应的语音片段,作为第二语音片段,如图7e所示。
168.图8的实施例的优点是,它采用句向量序列转换模块将子文本段的各语句转换成句向量,利用注意力模型获得各句向量的注意力分数,基于注意力分数来选取第一语音片段和第二语音片段,注意力分数高的语句重要性比较大,其体现出的情感相比于其它语句更能代表对象要真实表达的情感,因此,提高了情感变化识别的准确度。
169.然后,如图9所示,在步骤620中,将第一语音片段输入第一模型910,生成第一向量,并将第二语音片段输入第二模型920,生成第二向量。第一模型910和第二模型920具有同样的结构和参数。
170.向量是二进制数的序列,如0111
…
10001。第一模型910是将第一语音片段转换成第一向量的模型,如卷积神经网络(cnn)。第二模型920是将第二语音片段转换成第二向量的模型,如cnn。通过第一模型910和第二模型920生成第一向量和第二向量的意义在于,分类器930通常只能接收数字化的序列作为输入,经过运算,才能产生情感变化分类结果。作为文本的第一语音片段和第二语音片段,要通过第一模型910和第二模型920转换成相应的
第一向量和第二向量,才能输入分类器930进行情感变化分类。第一模型910和第二模型920具有同样的结构和参数。同样的结构和参数保证了第一向量和第二向量能够忠实体现第一语音片段和第二语音片段的固有性质。例如,第一语音片段和第二语音片段具有类似的情感类别,经具有相同结构和参数的第一模型910和第二模型920,就会产生相似度较大(欧式或余弦距离较小)的第一向量和第二向量,分类器930就会产生出情感变化不大的分类结果。
171.同样的结构和参数的含义是,第一模型910和第二模型920内部具有相同的处理节点,各处理节点具有相同的连接关系,各处理节点处理时采用相同的参数进行处理。以第一模型910和第二模型920都是cnn为例。众所周知,cnn包括输入层、多个隐藏层和输出层。输入层具有多个处理节点,每个处理节点具有权重矩阵(卷积核)。每个隐藏层也具有多个处理节点,每个处理节点也具有权重矩阵(卷积核)。输出层也具有多个处理节点,每个处理节点也具有权重矩阵(卷积核)。输入层的各处理节点将cnn的输入向量与自身的卷积核卷积,得到该处理节点的输出,作为下一层的隐藏层的各处理节点的输入。下一层的隐藏层的各处理节点将上一层各处理节点的输出与自身的卷积层卷积,得到该处理节点的输出,作为更下一层的隐藏层的各处理节点的输入。以此类推,直到输出层的各处理节点将最后一层的隐藏层的各处理节点的输出与自身的卷积层卷积,得到第一向量或第二向量。这里,同样的结构和参数意味着,两个cnn具有相同的层数,两个cnn的相应层具有相同个数的处理节点,两个cnn中相应的处理节点与上一层处理节点和下一层处理节点之间的连接关系相同,两个cnn中相应处理节点的卷积核相同。
172.第一模型910和第二模型920除了采用cnn之外,本公开实施例提出了一种更能提高情感变化识别准确率的第一模型910或第二模型920。该实施例中,如图10a-b所示,该第一模型910或第二模型920包括顺序连接的多个处理层1090和全连接层1093。第一个处理层1090接收第一向量或第二向量。每个处理层1090将处理后的结果输出到下一个处理层1090作为输入。最后一个处理层1090将处理后的结果输出到全连接层1093,由全连接层1093产生第一向量或第二向量。每个处理层1093包括两个组1010,每个组中包括多个处理节点1011、批量归一化模块1012和线性整流函数(relu)1013。
173.处理节点1011同cnn中的处理节点一样,执行输入向量或上一个处理层1090的输出向量与自身卷积核的卷积。
174.线性整流函数(relu)1013是一种激活函数。处理节点1011的卷积运算本质上是一种线性运算。如果仅有处理节点1011,无论有多少个处理层1090,每一个处理层1090都只是接收来自上一个处理层1090的输出向量进行线性组合,模型最终的输出仍然是模型输入的线性组合,不能够完成复杂的任务。如果允许处理节点1011的计算函数为任意函数,虽然可以设计出灵活、功能强大的模型,但是这样的模型过于复杂且难以训练,而且通用性差。为了兼顾计算的简单性、以及模型的灵活性,模型采用处理节点线性运算加激活函数非线性变换的方式。relu是一个分段线性函数,如果输入为正,它将直接输出,否则,它将输出为零。它的优点是使得模型更容易训练,并且通常能够获得更好的性能。
175.批量归一化模块1012对组1010内多个处理节点1011的输出向量执行批量归一化,以便输出到线性整流函数1013。一般来说,对于模型的输入通常会执行归一化处理,使得模型的输入遵循均值为u,方差为h的正态分布,这样能够加速模型的收敛。但是这个输入经过
处理节点1011的卷积后,卷积后的结果可能就不满足上述正态分布了。此时,将卷积后的结果输入线性整流函数1013,很可能一些卷积后的结果落入线性整流函数的饱和区,导致模型训练的梯度消失。批量归一化的含义是指使卷积后的结果重新满足正态分布,再输入线性整流函数1013就不会导致梯度消失。
176.全连接层1093起到将前面的层的输出向量映射成指定维度的第一向量或第二向量的作用。第一模型910或第二模型920有多个处理层1090,每个处理层1090有2个组1010,每个组有多个处理节点1011,产生巨大维度的向量输出。但第一向量或第二向量是指定维度的。全连接层1093起到将前面的层输出的巨大维度的向量映射成指定维度的向量的作用。全连接层1093包括多个全连接层节点1030。全连接层节点1030进行的也是卷积运算。它也具有卷积核。全连接层节点1030将前面的层的输出向量与自身的卷积核进行卷积。
177.图10a-b的模型结构的优点是,通过设置多个处理层1090,且让每个处理层1090包括两个组1010,增加了运算复杂度,提高模型处理的精确性。另外,在每个组1010内设置线性整流函数1013,使得模型能够适应复杂的非线性决策。在每个组1010内设置批量归一化模块1012,减轻了模型的梯度消失问题。
178.另外,如图10a-b所示,第一模型910或第二模型920在多个相邻的处理层1090之间设置池化层1091,相比于一般的cnn的单池化层1091结构,能进一步加快模型收敛速度。
179.池化层1091的主要作用是降维。每个处理层1090有2个组1010,每个组有多个处理节点1011,产生大量输出向量,这些向量具有大的维度。将这些向量直接输出到下一个处理层1090进行处理,将造成巨大的计算负担。因此,可以对处理节点1011输出的向量矩阵的某些分块用该分块的最大值或平均值等来代替,使得向量矩阵的维度减少,这叫做池化。每个池化层1091可以包括多个池化节点1020。每个池化节点1020对其负责的输入向量矩阵进行池化处理。
180.另外,如图10a-b所示,还可以在最后一个处理层1090和全连接层1093之间设置总体池化层1092。总体池化层1092的作用是在将所有处理层1090的最终输出向量矩阵发送到全连接层1093之前进行进一步降维,降低全连接层1093的处理负担。
181.另外,如图10a-b所示,全连接层1093可以有两层。在第一个全连接层1093中包含线性整流函数1013,用于增加全连接层1093输出结果的非线性,使得整个模型适应于模拟复杂操作。在第二个全连接层1093中包含s函数1040。s函数1040即sigmoid函数,也称为s型生长曲线。在信息科学中,由于其单增以及反函数单增等性质,s函数1040常被用作神经网络的激活函数,将变量映射到0,1之间。通过第二个全连接层1093能够完成二状态的判别。对于本公开实施例只需产生第一向量或第二向量而言,可以仅从第一个全连接层1093的输出中得到第一向量或第二向量。
182.图10b中可以看出,第一层处理层1090的每个组1010具有64个处理节点1011。第二层处理层1090的每个组1010具有128个处理节点1011。第三层处理层1090的每个组1010具有256个处理节点1011。第四层处理层1090的每个组1010具有512个处理节点1011。第五层处理层1090的每个组1010具有1024个处理节点1011。第六层处理层1090的每个组1010具有2048个处理节点1011。通过试验证明,这样的处理节点1011数目分布有助于提高模型收敛速度,提高模型处理精确度。
183.接着,在步骤630中,将第一向量和第二向量输入分类器930,由分类器930对第一
语音片段到第二语音片段的情感变化进行分类。这里的情感变化有两种含义。一种是情感状态的变化,情感状态包括有情感和无情感。情感状态的变化即从有情感变成无情感,从无情感变成有情感等。另一种是具体情感的变化,例如从高兴变成沮丧,从平静变成愤怒等。对于这两种情感变化的分类,分类器930的训练方式不同。这将在下文更加详细地描述。
184.图11a-b示出了分类器930的两种不同构成。
185.图11a所示的分类器930由一个全连接层构成。全连接层的概念在图10a-b的相关描述中已经说明。全连接层包含的全连接层节点931的数目与候选情感变化种类的数目一致。在情感变化为情感状态的变化的情况下,候选情感变化种类有无情感
→
有情感、有情感
→
无情感、无情感
→
无情感3种(之所以没有有情感
→
有情感,是由于有情感
→
有情感识别起来往往准确度不高)。这时,可以设置三个全连接层节点931。在情感变化为具体情感的变化的情况下,候选情感变化种类有q2种,其中q为候选情感的类型。这时,可以设置q2个全连接层节点931。例如,候选情感的类型有高兴、沮丧、愤怒、平静、生气、忧郁、激动7种,即第一语音片段的情感类型有7种,第二语音片段的情感类型有7种,第一语音片段到第二语音片段的情感变化种类有7
×
7=49种。设置49个全连接层节点931。
186.每个全连接层节点931对应一个情感变化种类。每个全连接层节点931接收第一向量和第二向量作为输入,与自身的卷积核进行卷积,卷积结果中包含全连接层节点931对应的情感变化种类的概率。多个全连接层节点931中输出概率最大的全连接层节点931对应的情感变化种类就是识别出的情感变化种类。以图11a为例,三个全连接层节点931中第一个全连接层节点931对应于无情感
→
有情感,第二个全连接层节点931对应于有情感
→
无情感,第三个全连接层节点931对应于无情感
→
无情感。第一个全连接层节点931输出概率为0.40,第二个全连接层节点931输出概率为0.64,第三个全连接层节点931输出概率为0.15。第二个全连接层节点931输出概率最高,则识别出第一语音片段到第二语音片段的情感变化种类是有情感
→
无情感。
187.图11b所示的分类器930与图11a的区别在于,它增加了聚合层932,用于将第一向量和第二向量拼接成一个向量后输入到各全连接层节点931。在图11a中,第一向量需要同时输入到多个全连接层节点931,第二向量也需要同时输入到多个全连接层节点931。在图11b中,第一向量和第二向量只需要输入到聚合层932一次,由聚合层932统一拼接成一个向量后,输出到多个全连接层节点931。图11b的结构大大提高了模型内部的数据流传输效率,降低了模型处理负荷。
188.通过上述步骤610-630,本公开实施例不是根据单独的语音片段识别情感,而是从时间上有先后关系的第一语音片段和第二语音片段中识别语音情感的变化,识别过程体现了语音的上下文,提高了识别的准确性。同时,它将第一语音片段输入第一模型910,生成第一向量,并将第二语音片段输入第二模型920,生成第二向量,而第一模型910和第二模型920具有同样的结构和参数,同样的结构和参数保证了第一向量和第二向量能够忠实体现第一语音片段和第二语音片段的固有性质,将这样得到的第一向量和第二向量输入分类器930,能够得到准确的情感变化识别结果。整个过程不依赖情感交互矩阵,不需要大量的情感标注数据,能高效地识别出语音情感的变化。
189.情感状态变化的识别
190.如上所述,本公开实施例中的情感变化识别可以指情感状态变化的识别,也可以
指具体情感变化的识别。两种情形下模型的训练方式不同。先详细介绍第一种情形。
191.在这种情形下,第一语音片段到第二语音片段的情感变化包括情感状态之间的跃迁。情感状态是指有无情感的状态,包括有情感和无情感。跃迁是指由一种情感状态进入另一种情感状态。跃迁前的情感状态与跃迁后的情感状态可以相同,也可以不同。例如,第一语音片段的情感状态是无情感,第二语音片段的情感状态也是无情感,这时也可以认为发生了跃迁,因为二者可能是在不同语境下的无情感。此时,情感变化的种类可能有无情感
→
有情感、有情感
→
无情感、无情感
→
无情感等。
192.在这种情形下,如图17所示,第一模型910、第二模型920和分类器930可以预先通过以下过程联合训练:
193.步骤1710、构建第一样本集;
194.步骤1720、将第一样本语音片段输入第一模型910,生成第一样本向量,并将第二样本语音片段输入第二模型920,生成第二样本向量;
195.步骤1730、将第一样本向量和第二样本向量输入分类器930;
196.步骤1740、基于分类器930的分类结果与第一样本标签的比较,构造第一误差函数,并基于第一误差函数调整第一模型910、第二模型920和分类器930的参数。
197.下面对步骤1710-1740进行详细描述。
198.步骤1710的第一样本集包括多个第一样本。第一样本的数目越多,训练效果越好。第一样本集中的每个第一样本包括第一样本语音片段和第二样本语音片段。第一样本语音片段是指从语音段中取出的、时间在前的用作样本的语音片段。第二样本语音片段是指从同一语音段中取出的、时间在后的用作样本的语音片段。这里的第一样本语音片段和第二样本语音片段类似于步骤610的第一语音片段和第二语音片段,只不过第一样本语音片段和第二样本语音片段用于模型训练,第一语音片段和第二语音片段用于模型的实际使用。
199.另外,这里的第一样本语音片段和第二样本语音片段可以是从同一语音段中同一个人的语音中提取出来的。语音段可能不仅包含一个人的语音,例如对话的情形。如果第一样本语音片段和第二样本语音片段是来自不同的两个人的语音片段,不同的人的情感本来可能就是不同的,这样分类器930分类出的就不是同一个人的情感变化,可能造成误识别。
200.事先为第一样本集中的第一样本打上标签,用于指示第一样本语音片段到第二样本语音片段情感状态之间的跃迁(例如,是无情感
→
有情感,还是有情感
→
无情感,还是无情感
→
无情感)。打标签可以采用人工标注的方式。
201.接着,在步骤1720,将每个第一样本的第一样本语音片段输入第一模型910,生成第一样本向量,并将第二样本语音片段输入第二模型920,生成第二样本向量。第一模型910和第二模型920就是步骤620中的第一模型910和第二模型920,需要具有相同的结构和参数。第一样本向量为第一样本语音片段转化成的二进制数序列,它能代表第一样本语音片段。第二样本向量为第二样本语音片段转化成的二进制数序列,它能代表第二样本语音片段。步骤1720的过程与步骤620是类似的,只不过这里输入第一模型910和第二模型920的是用于训练的第一样本语音片段和第二样本语音片段,第一模型910和第二模型920产生的是第一样本向量和第二样本向量;步骤620中输入第一模型910和第二模型920的是实际模型使用时的第一语音片段和第二语音片段,第一模型910和第二模型920产生的是第一向量和第二向量。
202.接着,在步骤1730,将第一样本向量和第二样本向量输入分类器930。这与步骤630是类似的,只不过这里输入分类器930的是模型训练中产生的第一样本向量和第二样本向量,在步骤630中输入分类器930的是模型使用中产生的第一向量和第二向量。对于每个第一样本,分类器930产生一个分类结果,即是无情感
→
有情感,还是有情感
→
无情感,还是无情感
→
无情感。
203.接着,在步骤1740,基于分类器930的分类结果与第一样本标签的比较,构造第一误差函数,并基于第一误差函数调整第一模型、第二模型和分类器的参数。
204.在一个实施例中,可以根据第一键和第一预测概率来构造第一误差函数。第一键是反映分类器930的分类结果与第一样本标签的比较结果的值。如果分类结果与第一样本标签相同,第一键可以是第一值(例如为1)。如果分类结果与第一样本标签不同,第一键可以是第二值(例如为2)。第一预测概率即分类器930中与分类结果对应的全连接层节点931输出的概率。如上面结合图11a-b所述,三个全连接层节点931中第一个全连接层节点931对应于无情感
→
有情感,它输出无情感
→
有情感这个分类结果的概率;第二个全连接层节点931对应于有情感
→
无情感,它输出有情感
→
无情感这个分类结果的概率;第三个全连接层节点931对应于无情感
→
无情感,它输出无情感
→
无情感这个分类结果的概率。这些概率即第一预测概率。
205.一般来说,第二值大于第一值。这是因为,分类结果与第一样本标签不同时的误差一定比分类结果与第一样本标签相同时的误差大。在分类结果与第一样本标签相同时,分类结果正确,但二者的分类误差可能仍有区别,因为分类器930在产生这个分类结果时全连接层节点931输出的概率可能不同。全连接层节点931输出的概率大的要比全连接层节点931输出的概率小的分类误差实际上更小。因此,第一误差函数不但要考虑第一键,还要考虑分类时的第一预测概率。
206.具体地,在一个实施例中,可以构造第一误差函数如下:
[0207][0208]
其中,n为第一样本集中第一样本的个数;hi为第i个第一样本的第一键;pi为对于第i个第一样本的第一预测概率。
[0209]
举一个简单的例子。假设第一样本集中只有3个第一样本。第一个第一样本的第一样本标签是无情感
→
有情感,经分类器930分类成了无情感
→
无情感,相应的第一预测概率为0.60。由于分类结果与第一样本标签不同,h1=2,p1=0.60。第二个第一样本的第一样本标签是无情感
→
无情感,经分类器930分类成了无情感
→
无情感,相应的第一预测概率为0.90。由于分类结果与第一样本标签相同,h2=1,p2=0.90。第三个第一样本的第一样本标签是有情感
→
无情感,经分类器930分类成了有情感
→
无情感,相应的第一预测概率为0.80。由于分类结果与第一样本标签相同,h3=1,p2=0.80。因此,得到l1=-2log0.60-log0.90-log0.80=1.95。
[0210]
上述根据第一键和第一预测概率来构造第一误差函数的优点是,使得第一误差函数既反映了分类结果与第一样本标签是否相同(即分类是否正确),还考虑到了在分类正确的情况下分类器930的全连接层节点931输出的第一预测概率带来的影响。在分类正确的情况下第一预测概率高的模型要比第一预测概率低的模型具有更精确的分类能力。因此,第一误差函数的构造更精细,有利于训练出分类效果更好的模型。
[0211]
另外,上述公式1也不是唯一的。例如,可以将公式1的对数运算去掉。但公式1相比于去掉对数运算的实施例,使第一预测概率对第一误差函数的影响不再是线性的,使模型训练过程能快速收敛。
[0212]
构造出第一误差函数后,可以基于第一误差函数调整第一模型910、第二模型920和分类器930的参数。具体地,可以预先设置第一阈值。当第一误差函数小于第一阈值时,训练过程结束。当第一误差函数大于或等于第一阈值时,调整第一模型910、第二模型920和分类器930的参数,直到第一误差函数小于第一阈值为止。第一模型910、第二模型的参数是指图10a-b中各处理层1090的处理节点1011的卷积核中的权重、池化层1091中的池化节点1020的卷积核中的权重、全连接层1093中的全连接层节点1030的卷积核中的权重等。注意,第一模型910和第二模型920的参数需要同步调节,以保持第一模型910和第二模型920的参数一致。分类器930的参数是指图11a-b中全连接层节点931的卷积核中的权重等。
[0213]
步骤1710-1740通过将第一模型910、第二模型920和分类器930联合训练,第一模型910、第二模型920和分类器930中的参数可以相互影响,提高了训练出的模型对语音情感变化的识别准确度。
[0214]
由于上述实施例只能识别情感状态的变化,即有情感和无情感之间的跃迁,无法识别对象的具体情感类别,如高兴、激动等。如果要识别对象的具体情感类别,在一个实施例中,可以采用如下方式识别第二语音片段的情感类别:
[0215]
如果分类出的情感变化为跃迁到有情感,获取第二语音片段的词向量序列;
[0216]
将词向量序列输入语义编码模型,得到第二语音片段的语义向量;
[0217]
将词向量序列和语义向量输入情感分类模型,得到第二语音片段的情感类别。
[0218]
下面结合图12对上述过程的具体实现进行描述。
[0219]
如图12的虚线所示,当分类出的情感变化为跃迁到有情感(如无情感
→
有情感、有情感
→
有情感等),启用图12的词向量序列获取模块1210。由词向量序列获取模块1210获取第二语音片段的词向量序列。词向量序列是指第二语音片段中的词对应的词向量级联成的序列。
[0220]
具体地,词向量序列获取模块1210可以包括第二语音识别模型1211和词向量序列转换模块1212。第二语音识别模型1211将第二语音片段的语音利用语音识别技术转换成文本。词向量序列转换模块1212将转换成的文本分成词,查找每个词的词向量,并将词向量按照词在文本中的顺序串接成词向量序列。第二语音识别模型1211类似于图8中的第一语音识别模型810。词向量序列转换模块1212类似于图8中的第一句向量序列转换模块830和第二句向量序列转换模块840。为节约篇幅,不再赘述。
[0221]
获得词向量序列后,可以将词向量序列输入图12的语义编码模型1220,得到第二语音片段的语义向量。语义向量是表示第二语音片段的语义的向量。它与词向量序列不同。词向量序列是孤立的每个词的词向量组成的序列,没有反映词之间的上下文关系,即语义。而语义向量反映了词和词之间的上下文关系,即语义。
[0222]
语义编码模型1220可以采用如图13所示的双向长短期记忆模型(bi-lstm)。它是循环神经网络(rnn)的一种。rnn的出现是为了克服卷积神经网络(cnn)中的每个层的处理节点只能根据该处理节点接收到的前一层的处理节点的输出进行卷积核运算、同层的处理节点的运算互不相关的问题。由于同层的处理节点的运算互不相关,导致有关上下文的信
lstm节点链路。正向bi-lstm节点链路的第一个正向bi-lstm节点h1和反向bi-lstm节点链路的第一个反向bi-lstm节点hn’接收语义向量作为初始状态向量。正向bi-lstm节点链路的每个正向bi-lstm节点除了接收相应词的注意力分数之外,还接收前一个正向bi-lstm节点输出的状态向量。同时,每个正向bi-lstm节点还产生自身的状态向量,作为正向bi-lstm节点链路上后一个正向bi-lstm节点的输入。反向bi-lstm节点链路的每个反向bi-lstm节点除了接收相应词的注意力分数之外,还接收前一个反向bi-lstm节点输出的状态向量。同时,每个反向bi-lstm节点还产生自身的状态向量,作为反向bi-lstm节点链路上后一个正向bi-lstm节点的输入。
[0228]
除了图14的结构之外,情感分类模型1230还可以采用其它的结构。图14的结构相比于其它结构的优势在于,它充分了考虑了识别情感类别时每个词的不同贡献,结合注意力分数和语义向量共同确定情感类别,提高情感类别识别的准确性。
[0229]
除了图12的词向量序列获取模块1210、语义编码模型1220、情感分类模型1230之外,也可以采用其它方式识别第二语音片段的具体情感类别。相比于其它方式,图12的结构在情感类别的识别中不但考虑到每个词,还紧密结合第二语音片段转换成的文本的语义,利用词向量序列和语义向量共同确定第二语音片段的情感类别,提高了情感类别识别的准确性。
[0230]
变化前后具体情感类别的识别
[0231]
在如上所述的情感变化识别的第二种情形中,情感变化识别是指具体情感变化的识别,如高兴
→
愤怒。下面详细介绍这种情形。
[0232]
在这种情形下,第一语音片段到第二语音片段的情感变化包括第一语音片段的情感类别和第二语音片段的情感类别。如上例中的高兴
→
愤怒,第一语音片段的情感类别是“高兴”,第二语音片段的情感类别是“愤怒”。
[0233]
在这种情形下,如图18所示,第一模型910、第二模型920和分类器930预先通过以下过程联合训练:
[0234]
步骤1810、构建第二样本集;
[0235]
步骤1820、将第三样本语音片段输入第一模型910,生成第三样本向量,并将第四样本语音片段输入第二模型920,生成第四样本向量;
[0236]
步骤1830、将第三样本向量和第四样本向量输入分类器930;
[0237]
步骤1840、基于分类器940的分类结果与第二样本标签的比较,构造第二误差函数,并基于第二误差函数调整第一模型910、第二模型920和分类器930的参数。
[0238]
下面对步骤1810-1840进行详细描述。
[0239]
步骤1810中,第二样本集中包括多个第二样本,每个第二样本包括第三样本语音片段和第四样本语音片段。第二样本具有第二样本标签,用于指示第三样本语音片段的情感类别和第四样本语音片段的情感类别。
[0240]
这里的第二样本集类似于步骤1710中的第一样本集,第三样本语音片段和第四样本语音片段类似于步骤1710中的第一样本语音片段和第二样本语音片段。第三样本语音片段和第四样本语音片段可以是从同一语音段中同一个人的语音中提取出来的,且第三样本语音片段在第四样本语音片段之前。为节约篇幅,不再赘述。这里的第二样本标签与步骤1710中的第一样本标签的区别在于,第一样本标签只能指示情感状态之间的跃迁(例如无
情感
→
有情感),不能只是具体是从什么情感到什么情感,而第二样本标签指示具体从什么情感到什么情感,即指示第三样本语音片段的情感类别和第四样本语音片段的情感类别。
[0241]
步骤1820中的第三样本向量和第四样本向量与图1720中的第一样本向量和第二样本向量类似。将第三样本语音片段输入第一模型910,生成第三样本向量,并将第四样本语音片段输入第二模型920,生成第四样本向量的过程,与步骤1720中的将第一样本语音片段输入第一模型910,生成第一样本向量,并将第二样本语音片段输入第二模型920,生成第二样本向量的过程类似,故不赘述。
[0242]
步骤1830中的将第三样本向量和第四样本向量输入分类器930,与步骤1730中的将第一样本向量和第二样本向量输入分类器930类似,故不赘述。
[0243]
步骤1840的实现方式与步骤1740类似。它也可以采用根据第一键和第一预测概率来构造第一误差函数的方式。与步骤1740不同的是,这里的第一键是指示分类器930的分类结果与第二样本标签的比较结果的值。分类器930的分类结果与第二样本标签相同,意味着分类器930预测出的第一语音片段的情感类别与第二样本标签中的第一语音片段的情感类别相同,分类器930预测出的第二语音片段的情感类别与第二样本标签中的第二语音片段的情感类别相同。例如,第二样本标签是高兴
→
愤怒,如果分类器930的分类结果也是高兴
→
愤怒,则分类器930的分类结果与第二样本标签相同。如果分类器930的分类结果也是高兴
→
沮丧,尽管第一语音片段的情感类别预测成功,仍然不能认为分类器930的分类结果与第二样本标签相同。
[0244]
可以按照类似上面公式1的方式构造第二误差函数。构造第二误差函数后,也可以按照与步骤1740类似的方式,基于第二误差函数调整第一模型910、第二模型920和分类器930的参数,故不赘述。
[0245]
图18的实施例的优点是,它直接训练出能识别变化前的具体情感和变化后的具体情感的第一模型910、第二模型920和分类器930,这在不仅需要知晓对象的情感是否有变化,还需要知晓是什么情感变化到什么情感的一些应用中提高了情感识别效率。
[0246]
结合域对抗模型的方案
[0247]
域对抗是迁移学习的一个重要分支,用于消除不同域之间的特征分布差异,从而提高模型的识别精确性。它通过产生其它域的混淆样本,来训练模型,使模型具有在即使有大量混淆样本的情况下仍然能保持一定识别准确率的能力。
[0248]
具体到本公开实施例中,除了将同一说话人的前后说出的不同语音片段作为样本,还将不同说话人说出的语音片段作为用于混淆的样本,共同训练第一模型910、第二模型920、分类器930等。同一说话人的语音片段可以看作是处于同一个域。不同说话人的语音片段可以看作是处于不同域,作为混淆放入样本中,对分类器930的训练具有对抗作用,通过这种对抗提高分类器930的识别准确性,因此叫做域对抗。
[0249]
如图15所示,引入说话者判决器940对这些样本是同一说话人发出的、还是不同说话人发出的进行判决。分类器930根据样本中前后的语音片段,得到情感变化的分类结果,该分类会有一定的误差。说话者判决器940判决样本中前后的语音片段的发出者是否相同,该判决也会有一定误差。综合分类器930产生的分类误差和说话者判决器940产生的判决误差,共同训练第一模型910、第二模型920、分类器930和说话者判决器940,就既能够提高分类器930分类的准确率,也能够提高说话者判决器940判决的准确率。尤其是,由于在样本中
引入不同说话人的语音片段作为混淆,提高了分类器930抗混淆的能力。
[0250]
说话者判决器940接收第一向量和第二向量作为输入,产生第一语音片段的发出者和第二语音片段的发出者是否相同的判决结果。例如,第一语音片段的发出者和第二语音片段的发出者相同,用1表示;第一语音片段的发出者和第二语音片段的发出者不同,用0表示。
[0251]
图16示出了说话者判决器940的一种具体结构。它包括比较器941、第一隐马尔科夫模型942和第二隐马尔科夫模型943。第一隐马尔科夫模型942接收第一向量作为输入,将第一向量与事先已准备好的各种说话者的声音特征向量模板(说话者1声音特征向量模板、说话者2声音特征向量模板
……
说话者n声音特征向量模板)进行比较。如果与其中的一个声音特征向量模模板匹配,将该声音特征向量模板对应的说话者作为识别出的说话者。第一隐马尔科夫模型943接收第二向量作为输入,将第二向量与事先已准备好的各种说话者的声音特征向量模板进行比较。如果发现匹配,将匹配的声音特征向量模板对应的说话者作为识别出的说话者。比较器941将第一隐马尔科夫模型942识别出的说话者与第二隐马尔科夫模型943识别出的说话者进行比较。如果二者一致,则判定第一语音片段的发出者和第二语音片段的发出者相同,即结果1;如果二者不一致,则判定第一语音片段的发出者和第二语音片段的发出者不同,即结果0。
[0252]
隐马尔可夫模型(hidden markov model,hmm)是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可预测的状态序列,再由各个状态生成一个观测值从而产生观测值随机序列的过程。隐马尔可夫模型就是要从观测值随机序列推理回状态序列。例如,有3种骰子,分别有4、6和8个面,4个面的骰子在4个面上印有0、1、2、3,6个面的骰子在6个面上印有0、1、2、3、4、5,8个面的骰子在8个面上印有0、1、2、3、4
……
7。如果掷了3次骰子,得到2-7-4,需要猜测3次分别掷的是哪一种骰子。上述的2-7-4相当于观测值随机序列,每次掷的是哪一种骰子相当于状态序列。从观测值随机序列反推状态序列的过程即隐马尔可夫模型求解过程。对于说话者识别来说,每个说话者具有说话者声音特征,但这个特征由于每句话的声音大小、语速、情感不同,它具有不同的表象。第一隐马尔科夫模型942或第二隐马尔科夫模型943就是要从第一向量或第二向量蕴含的声音表象中预测是哪一种声音特征模板表现出来的,从而预测第一语音片段的发出者或第二语音片段的发出者。
[0253]
除了图16的结构,说话者判决器940也可以采用其它方式实现。图16的结构相比于其它方式,能够挖掘声音表象后面隐藏的说话者声音特征,从而提高关于说话者是否相同的预测准确性。
[0254]
如图19所示,在一个实施例中,第一模型910、第二模型920、分类器930和说话者判决器940预先通过以下过程联合训练:
[0255]
步骤1910、构建第三样本集;
[0256]
步骤1920、将第五样本语音片段输入第一模型910,生成第五样本向量,并将第六样本语音片段输入第二模型920,生成第六样本向量;
[0257]
步骤1930、将第五样本向量和第六样本向量输入分类器930,并将第五样本向量和第六样本向量输入说话者判决器940;
[0258]
步骤1940、基于分类器930的分类结果与第三样本标签的比较、说话者判决器940的判定结果与第四样本标签的比较,构造第三误差函数,并基于第三误差函数调整第一模
型910、第二模型920、分类器930和说话者判决器940的参数。
[0259]
下面对步骤1910-1940进行详细描述。
[0260]
步骤1910的第三样本集包括多个第三样本,每个第三样本包括第五样本语音片段和第六样本语音片段。第五样本语音片段和第六样本语音片段可以是从同一语音段中提取的两个语音片段,且第五样本语音片段在第六样本语音片段之前。这与步骤1710中的第一样本包括第一样本语音片段和第二样本语音片段、步骤1810中的第二样本包括第三样本语音片段和第四样本语音片段是类似的。与步骤1710和步骤1810不同,这里的第五样本语音片段和第六样本语音片段可以是不同人的语音片段。例如,语音段是两个人或更多人交谈的语音段。第五样本语音片段来自交谈中的一个人,第六样本语音片段来自交谈中的另一个人。混入来自不同人的语音片段的样本,如上所述,是为了形成域对抗,以此训练模型,使模型具有在即使有混淆样本的情况下仍然能保持一定识别准确率的能力。
[0261]
每个第三样本具有第三样本标签和第四样本标签。第三样本标签是用于指示第五样本语音片段到第六样本语音片段的情感变化的标签(例如无情感
→
有情感、或高兴
→
愤怒)。它用于在之后的步骤1940中衡量分类器930的分类误差。第四样本标签是用于指示第五样本语音片段的发出者和第六样本语音片段的发出者是否相同的标签(例如“相同”用1表示,“不同”用0表示)。它用于在之后的步骤1940中衡量说话者判决器940的判决误差。
[0262]
步骤1920中,将第五样本语音片段输入第一模型910,生成第五样本向量,并将第六样本语音片段输入第二模型920,生成第六样本向量,与步骤1720中将第一样本语音片段输入第一模型910,生成第一样本向量,并将第二样本语音片段输入第二模型920,生成第二样本向量,是类似的。为节约篇幅,不再赘述。
[0263]
步骤1930中的将第五样本向量和第六样本向量输入分类器930,与步骤1730中的将第一样本向量和第二样本向量输入分类器930是类似的。但在步骤1930,还要将第五样本向量和第六样本向量输入说话者判决器940。分类器930需要根据第五样本向量和第六样本向量产生情感变化分类结果,说话者判决器940需要根据第五样本向量和第六样本向量判决第一样本语音片段的说话者和第二样本语音片段的说话者是否相同。
[0264]
分类器930产生情感变化分类结果时会有分类误差,说话者判决器940在判决说话者是否相同时会有分类误差,现有技术中会根据各自的误差单独训练分类器930及说话者判决器940。训练分类器930时没有考虑说话者判决误差的影响,训练说话者判决器940时没有考虑情感变化分类的影响,造成训练出的模型不够鲁棒,准确性不高。本公开实施例在步骤1940中,采用将分类误差和判决误差综合考虑,让其相互影响的方式,训练出的分类器930和说话者判决器940足够鲁棒,提高情感变化分类准确性。具体地,基于分类器930的分类结果与第三样本标签的比较、说话者判决器940的判定结果与第四样本标签的比较,构造第三误差函数,并基于第三误差函数调整第一模型910、第二模型920、分类器930和说话者判决器940的参数。
[0265]
在一个实施例中,如图20所示,上述构造第三误差函数的过程具体包括:
[0266]
步骤2010、基于分类器930的分类结果与第三样本标签的比较,构造第一误差子函数;
[0267]
步骤2020、基于说话者判决器940的判定结果与第四样本标签的比较,构造第二误差子函数;
[0268]
步骤2030、基于第一误差子函数与第二误差子函数,构造第三误差函数。
[0269]
下面对步骤2010-2030进行详细描述。
[0270]
第一误差子函数是反映分类器930的分类误差的函数,它体现了分类器930的分类结果与第三样本标签的比较结果。第二误差子函数是反映说话者判决器940的判决误差的函数,它体现了说话者判决器940的判决结果与第四样本标签的比较结果。第三误差函数是综合体现分类器930的分类误差和说话者判决器940的判决误差的函数。
[0271]
在一个实施例中,步骤2010包括:
[0272]
针对第三样本集中的第三样本,构造第一键,其中,第一键为第一值时指示分类器930的分类结果与第三样本标签相同,第一键为第二值时指示分类器930的分类结果与第三样本标签不同;
[0273]
获取分类器930对分类结果的第一预测概率;
[0274]
基于第一键和第一预测概率,构造第一误差子函数。
[0275]
这里的第一键与步骤1740中构造第一误差函数时用的第一键类似。与步骤1740中构造第一误差函数时用的第一键不同的是,步骤1740中构造第一误差函数时,第一键表示的是分类器930的分类结果与第一样本标签是否相同,这里的第一键表示的是分类器930的分类结果与第三样本标签是否相同。
[0276]
这里的第一预测概率也与步骤1740构造第一误差函数的过程中的第一预测概率含义一致。
[0277]
这里的基于第一键和第一预测概率,构造第一误差子函数,也与步骤1740中构造第一误差函数中构造第一误差函数的过程类似,例如通过如下公式:
[0278][0279]
公式2与公式1的区别仅在于用lc1取代了l1,因为l代表的是误差函数,而lc代表误差子函数。hi代表第一键。如果分类结果与第三样本标签相同,第一键hi可以是第一值(例如为1)。如果分类结果与第三样本标签不同,第一键hi可以是第二值(例如为2)。pi代表第一预测概率。
[0280]
上述构造第一误差子函数的实施例的优点是,不但考虑了分类是否正确(即分类结果与第三样本标签是否相同,体现为公式2的hi),还考虑到了在分类正确的情况下分类器930的全连接层节点931输出的第一预测概率带来的影响(体现为公式2的pi)。尽管分类正确,第一预测概率大的分类结果实际上要比第二预测概率小的分类结果预测得更为精准。因此,上述实施例更有利于提高分类器930的分类准确性。
[0281]
接着,在步骤2020中,基于说话者判决器940的判定结果与第四样本标签的比较,构造第二误差子函数。在一个实施例中,步骤2020包括:
[0282]
针对第三样本集中的第三样本,构造第二键,其中,第二键为第一值时指示说话者判决器的判定结果与第四样本标签相同,第二键为第二值时指示说话者判决器的判定结果与第四样本标签不同;
[0283]
获取说话者判决器对判定结果的第二预测概率;
[0284]
基于第二键和第二预测概率,构造第二误差子函数。
[0285]
第二键是反映说话者判决器940的判决结果与第三样本标签的比较结果的值。如果判决结果与第三样本标签相同(例如判决结果是第一语音片段的发出者和第二语音片段
的发出者相同,第三样本标签也指示第一语音片段的发出者和第二语音片段的发出者相同),第二键可以是第一值(例如为1)。如果判决结果与第三样本标签不同,第二键可以是第二值(例如为2)。第二值大于第一值的原因是,判决结果与第三样本标签不同时的判决误差比判决结果与第三样本标签相同时的判决误差大。
[0286]
第二预测概率即图16的比较器941输出的第一语音片段与第二语音片段相同的概率。第一隐马尔可夫模型942或第二隐马尔可夫模型943向比较器941输出的并非是唯一的识别结果。其输出的可能是多个识别结果,每个识别结果带有一个预测概率。比较器941根据第一隐马尔可夫模型942和第二隐马尔可夫模型943各自输出的多个识别结果和相应的预测概率,综合得出第一语音片段与第二语音片段是否相同、以及二者相同的概率。例如,第一隐马尔可夫模型942向比较器941输出的是:说话者3,预测概率70%;说话者2,预测概率10%;说话者6,预测概率8%
……
第二隐马尔可夫模型943向比较器941输出的是:说话者3,预测概率80%;说话者1,预测概率10%;说话者5,预测概率5%
……
这时,比较器941的识别结果可能是第一语音片段和第二语音片段的发出者相同(都是说话者3),但第二预测概率可能既不是70%,也不是80%,而是根据上述第一隐马尔可夫模型942和第二隐马尔可夫模型943各自输出的多个识别结果的预测概率,利用统计学规律重新计算的。
[0287]
基于第二键和第二预测概率,构造第二误差子函数,与基于第一键和第一预测概率,构造第一误差子函数类似,可以通过以下公式:
[0288][0289]
lc2代表第二误差子函数。li代表第二键。qi代表第二预测概率。
[0290]
上述构造第二误差子函数的实施例的优点是,不但考虑了说话人是否相同的判决结果是否正确(体现为公式3的li),还考虑到了在判决结果正确的情况下第二预测概率带来的影响(体现为公式3的qi),有利于提高说话者判决器940的判决准确性。
[0291]
接着,在步骤2030中,基于第一误差子函数与第二误差子函数,构造第三误差函数。
[0292]
在一个实施例中,可以令第三误差函数等于第一误差子函数与第二误差子函数的和,即:
[0293][0294]
其中,l3表示第三误差函数。
[0295]
在另一个实施例中,可以令第三误差函数等于第一误差子函数与第二误差子函数的加权和,即:
[0296][0297]
其中,α为第一误差子函数的权重,β为第一误差子函数的权重。α和β可以事先根据经验人为设置。
[0298]
该加权和的实施例充分考虑到了在不同的场景下,衡量总体误差时对情感变化的分类结果和对说话人是否相同的判决结果的重视度可能会不同,因此可以在不同的场景下根据需要设置不同的权重,能够提高第三误差函数设置的灵活性,从而进一步提高情感变化分类准确性。
[0299]
在某些情况下,公式5可以简化成如下公式:
[0300][0301]
也就是说,仅设置第二误差子函数的权重,而将第一误差子函数的权重默认为1,由于α和β的绝对数值并无意义,重要的是α和β的大小相对关系,因此将α和β二个权重简化成一个权重γ,有利于简化计算,同时保持高的设置灵活性。
[0302]
基于第三误差函数调整第一模型910、第二模型920、分类器930和说话者判决器940的参数与步骤1740中基于第一误差函数调整第一模型910、第二模型920和分类器930的参数的方法类似,故不赘述。需要注意的是,第一模型910和第二模型920的参数需要同步调节。
[0303]
步骤2010-2030的优点在于,它针对分类器930分类的误差构造第一误差子函数,针对说话者判决器940判决的误差构造第二误差子函数,并基于第一误差子函数与第二误差子函数,构造第三误差函数。这样构造的第三误差函数综合反映了情感变化的分类误差和说话者是否相同的判决误差两者,提高训练出的分类器930的分类准确性。
[0304]
步骤1910-1940综合考虑了情感变化分类的误差和说话者是否相同的判决误差来联合训练第一模型910、第二模型920、分类器930和说话者判决器940,说话者是否相同的判决结果与情感分类的结果之间形成一种对抗,通过对抗提高了分类器930在各种情况下准确识别情感变化类型的能力,提高情感变化分类准确性。
[0305]
情感特征的增强
[0306]
上述实施例中,根据第一语音片段转换成的第一向量和第二语音片段转换成的第二向量进行情感变化分类,第一向量体现的是第一语音片段本身,第二向量体现的是第二语音片段本身。在一个实施例中,可以利用第一语音片段和第二语音片段中提取出的情感特征对第一向量和第二向量进一步增强,增强后的第一向量和第二向量更有利于提高情感变化分类的准确性。
[0307]
在该实施例中,如图21所示,在步骤620之后,该方法还包括:
[0308]
步骤628、从第一语音片段中提取第一情感特征序列,从第二语音片段中提取第二情感特征序列;
[0309]
步骤629、将第一情感特征序列并入第一向量,将第二情感特征序列并入第二向量。
[0310]
情感特征是指语音片段中提取出的与情感识别有关的特征,例如短时能量、过零率、梅尔倒谱系数等。第一情感特征序列是指从第一语音片段中提取出的多个情感特征级联产生的序列。第二情感特征序列是指从第二语音片段中提取出的多个情感特征级联产生的序列。
[0311]
短时能量是指在语音片段在一个很短的时间段内(如1秒内、或1帧内)的能量,它体现为图1a-e的波形在该时间段内的功率的积分。它可以每隔预定时间段周期性地提取,例如每秒提取一次。短时能量比较高,很可能说明对象正经历着愤怒、激动等,因此,短时能量有助于情感变化的分类。将它提取出来加入第一向量,有助于提高分类器930最终的情感变化分类的准确性。
[0312]
过零率是指的语音片段在单位时间内经过零点的次数(即符号发生变化的次数)。经过一次零点,意味着语音片段的幅度的符号发生一次变化,因此过零率可以反映语音片段的幅度符号变化的频率。在对象比较愤怒、激动等,说话比较快,过零率比较大。在对象比
较沮丧时,说话比较慢,过零率比较小。因此,过零率也有助于情感变化的分类。将它提取出来加入第一向量,有助于提高分类器930最终的情感变化分类的准确性。
[0313]
梅尔倒谱系数(mel-scale frequency cepstral coefficient,简称mfcc)是在梅尔标度频率域提取出来的倒谱参数,描述了人耳频率的非线性特性。人耳对不同频率的声波有不同的听觉敏感度。两个响度不等的声音作用于人耳时,则响度较高的频率成分的存在会影响到对响度较低的频率成分的感受,使其变得不易察觉,这种现象称为掩蔽效应。一般来说,低音容易掩蔽高音,而高音掩蔽低音较困难。因此,从低频到高频这一段频带内按临界带宽的大小由密到疏安排一组带通滤波器,对输入声波信号进行滤波。将每个带通滤波器输出的信号能量作为信号的基本特征,即梅尔倒谱系数。当对象由于激动而发出尖叫等高频声音时,与对象沮丧时发出的沉闷的低频声音时,梅尔倒谱系数显然是不同的。梅尔倒谱系数也有助于情感变化的分类。将它提取出来加入第一向量,有助于提高分类器930最终的情感变化分类的准确性。
[0314]
图22示出了实现上述实施例的一种具体结构。步骤628的从第一语音片段中提取第一情感特征序列、从第二语音片段中提取第二情感特征序列是由第一情感特征序列提取模块2210、第二情感特征序列提取模块2220实现的。第一情感特征序列提取模块2210包括第一情感特征提取模块2211和第一序列化模块2212。第二情感特征序列提取模块2220包括第二情感特征提取模块2221和第二序列化模块2222。
[0315]
第一情感特征提取模块2211用于从第一语音片段中提取情感特征,如上所述的短时能量、过零率、梅尔倒谱系数等。针对提取的情感特征不同,第一情感特征提取模块2211有相应的结构。第一情感特征提取模块2211提取的情感特征往往是数值型的,例如短时能量体现为能量值,而数值型的参数作为模型输入有困难,且不能融入到已形成的第一向量中去,因此通过第一序列化模块2212将数值型的情感特征变为二进制数序列,即第一情感特征序列。第一序列化模块2212的作用即执行数值到二进制数序列的转换。
[0316]
同理,第二情感特征提取模块2221用于从第二语音片段中提取情感特征。然后,通过第二序列化模块2222将提取的情感特征变为二进制数序列,即第二情感特征序列。
[0317]
然后,在步骤629中,将第一情感特征序列并入第一向量,将第二情感特征序列并入第二向量。并入第一向量或第二向量的位置可以是在第一向量或第二向量的末尾或开头。也可以规定,在第一向量或第二向量中间的某个位置并入第一情感特征序列或第二情感特征序列。例如,在第一向量或第二向量前10个比特之后,等等。
[0318]
图22的实施例的好处在于,对情感变化分类时,不仅仅依据第一语音片段和第二语音片段本身的表达,还依据其中提取出的能宏观反映第一语音片段和第二语音片段的一些情感特征(如短时能量、过零率等),提高了情感变化分类的准确性。
[0319]
多个语音片段情感变化的识别
[0320]
如上所述的实施例中,一般是从语音段中提取两个有前后关系的语音片段(第一语音片段和第二语音片段)输入到第一模型910、第二模型920、分类器930进行情感变化识别,但也可以从语音段中提取超过两个有前后关系的语音片段进行连续的情感变化识别,例如根据三个有前后关系的语音片段识别出情感变化为平静
→
平静
→
沮丧,根据四个有前后关系的语音片段识别出情感变化为高兴
→
沮丧
→
沮丧
→
高兴。为了简化起见,下面仅以根据三个有前后关系的语音片段识别出情感变化类型进行说明,本领域技术人员可以根据
下面根据三个有前后关系的语音片段识别出情感变化类型的实施例的描述,构造出根据更多有前后关系的语音片段识别出情感变化类型的实施例。
[0321]
在一个实施例中,在步骤630之前,本公开的语音情感变化识别方法还可以包括:
[0322]
获取第三语音片段,第三语音片段与第二语音片段来自于同一语音段,且在第二语音片段之后;
[0323]
将第三语音片段输入第三模型950,生成第三向量,其中,第三模型950与第二模型920具有同样的结构和参数;
[0324]
另外,步骤630可以包括:将第一向量、第二向量和第三向量输入分类器930,由分类器930对第一语音片段到第二语音片段的情感变化进行分类,并对第二语音片段到第三语音片段的情感变化进行分类。
[0325]
第三语音片段是在第二语音片段之后的另一个语音片段。第一语音片段、第二语音片段和第三语音片段取自同一语音段,且时间先后顺序从早到晚为:第一语音片段、第二语音片段、第三语音片段。可以按照与步骤610中获取第一语音片段和第二语音片段类似的方法获取第三语音片段,如图7a-e的方法。
[0326]
第三向量是第三语音片段转换成的二进制数序列。可以按照与步骤620将第一语音片段输入第一模型910得到第一向量、将第二语音片段输入第二模型920得到第二向量类似的方法,如图23所示,将第三语音片段输入第三模型950,生成第三向量。第一模型910、第二模型920和第三模型950具有同样的结构和参数。
[0327]
图23的分类器930采取图11b所示的聚合层932加全连接层节点931的结构。聚合层932包括两个聚合模块933。第一个聚合模块933负责第一向量和第二向量的聚合,以便进行第一语音片段到第二语音片段的情感变化分类。第二个聚合模块933负责第二向量和第三向量的聚合,以便进行第二语音片段到第三语音片段的情感变化分类。全连接层节点931对于第一语音片段到第二语音片段的情感变化分类、第二语音片段到第三语音片段的情感变化分类也是分开的。假设有三种情感变化分类,即从无情感
→
有情感、有情感
→
无情感、无情感
→
无情感,对于第一语音片段到第二语音片段的情感变化分类,设置3个全连接层节点931,与第一个聚合模块933对应;对于第二语音片段到第三语音片段的情感变化分类,设置3个全连接层节点931,与第二个聚合模块933对应。
[0328]
当第一个聚合模块933接收到来自第一模型910的第一向量和来自第二模型920的第二向量后,将第一向量和第二向量聚合,输入到与第一个聚合模块933对应的多个全连接层节点931,由多个全连接层节点931确定出第一语音片段到第二语音片段的情感变化分类。当第二个聚合模块933接收到来自第二模型920的第二向量和来自第三模型950的第三向量后,将第二向量和第三向量聚合,输入到与第二个聚合模块933对应的多个全连接层节点931,由多个全连接层节点931确定出第二语音片段到第三语音片段的情感变化分类。例如,第一语音片段到第二语音片段的情感变化分类为无情感
→
无情感,第二语音片段到第三语音片段的情感变化分类为无情感
→
有情感,则第一语音片段、第二语音片段、第三语音片段的情感变化分类为无情感
→
无情感
→
有情感。
[0329]
本领域技术人员可以受益于上述识别第一语音片段、第二语音片段、第三语音片段的情感变化的实施例,构造出从更多语音片段(例如,四个、五个等)识别出情感变化的实施例。
[0330]
通过上述实施例,能够从时间上有先后关系的多个语音片段中同时识别出多个语音片段间的情感变化,相比于将每两个时间上有先后关系的语音片段陆续输入图9的结构进行情感变化分类的方案,大大提高了识别效率。
[0331]
根据不同情感变化的定制化响应
[0332]
本公开实施例除了能够识别语音片段的情感变化,还能够根据识别出的不同情感变化,进行定制化响应。这些定制化响应大大丰富了本公开实施例在具体场景中的实际应用效果。
[0333]
如图24所示,在一个实施例中,在步骤630之后,本公开实施例的语音情感变化识别方法还包括:
[0334]
步骤640、根据分类器930的情感变化分类结果,确定对情感变化分类结果的响应;
[0335]
步骤650、执行响应。
[0336]
如图25所示,当对象说话时,借助于本公开实施例的录音模块采集对象说话的声音,作为语音段。然后,利用如图6所示的方法从语音段中提取第一语音片段和第二语音片段,进行情感变化的识别,识别出从第一语音片段到第二语音片段的情感变化,由响应决策模块确定对该情感变化的响应,并执行响应。确定响应和执行响应的具体过程将结合如下四种应用场景进行详述。
[0337]
(一)贴身情绪管家
[0338]
贴身情绪管家一般安装在对象随身携带的终端140(如手机)中。终端140实时采集对象的语音,并识别其中的情感变化,并根据对象的情感变化采取适当的安抚策略,例如放音乐和播放安抚语音。
[0339]
在该场景下,步骤640包括:根据分类器930识别出的情感变化,确定与该情感变化对应的音乐类型和语料类型中的至少一种;步骤650包括:根据确定的音乐类型和语料类型中的至少一种,搜索该音乐类型的音乐和该语料类型的语料中的至少一种进行播放。
[0340]
图26是根据本公开的实施例的语音情感变化识别方法应用在贴身情绪管家场景下的模块构架图。除了第一模型910、第二模型920、分类器930之外,该构架还包括音乐/语料类型判决模块2610、搜索模块2620、曲库2630、语料素材库2660、媒体播放器2640、显示器2650等。
[0341]
上述根据分类器930识别出的情感变化,确定与该情感变化对应的音乐类型和语料类型中的至少一种的过程可以由音乐/语料类型判决模块2610执行。具体地,音乐/语料类型判决模块2610中可以预先设置有若干规则,这些规则指示了针对一种情感变化,应为其确定音乐类型,还是确定语料类型,还是既确定音乐类型又确定语料类型。例如,规则中可以规定:
[0342]
1)当识别出情感变化为平静
→
沮丧时,确定播放的音乐类型为大自然音乐;
[0343]
2)当识别出情感变化为平静
→
愤怒时,确定语料类型为平息愤怒型语言;
[0344]
3)当识别出情感变化为平静
→
忧郁时,预定音乐类型为欢快的音乐,语料类型为激励性语言。
[0345]
对于1),如果分类器930识别出的情感变化就是平静
→
沮丧,不确定语料类型,只将该情感变化对应的音乐类型确定为大自然音乐;对于2),如果分类器930识别出的情感变化就是平静
→
愤怒,不确定音乐类型,只将该情感变化对应的语料类型确定为平息愤怒型
语言;对于3),如果分类器930识别出的情感变化就是平静
→
忧郁,将音乐类型确定为欢快的音乐,将语料类型确定为激励性语言。
[0346]
上述根据确定的音乐类型和语料类型中的至少一种,搜索该音乐类型的音乐和该语料类型的语料中的至少一种的过程可以由搜索模块2620实现。各种音乐类型的音乐事先存储在曲库2630中,各种语料类型的语料事先存储在语料素材库2660中。当音乐/语料类型判决模块2610只确定了音乐类型时,搜索模块2620从曲库2630中搜索相应类型的音乐。例如,对于上述1),搜索模块2620从曲库2630中搜索大自然音乐,得到一首班得瑞的曲子。当音乐/语料类型判决模块2610只确定了语料类型时,搜索模块2620从语料素材库2660中搜索相应类型的语料。例如,对于上述2),搜索模块2620从曲库2630中搜索平息愤怒型语言,得到“息怒,不要用别人的错误惩罚自己”。当音乐/语料类型判决模块2610既确定了音乐类型,又确定了语料类型时,搜索模块2620既从曲库2630搜索相应音乐类型的音乐,又从语料素材库2660搜索相应语料类型的语料。例如,对于上述3),搜索模块2620从曲库2630中搜索欢快的音乐,得到《小苹果》,从语料素材库2660中搜索激励性语言,得到“外面天那么蓝,出去走走吧”。
[0347]
搜索模块2620搜索到相应音乐类型的音乐和相应语料类型的语料后,将其传送给媒体播放器2640播放。同时,可以在显示器2650(例如手机屏幕)上显示一些提示信息,如图2b的“识别出您的情感状态:平静到悲伤。将为您播放大自然音乐”。
[0348]
该贴身情绪管家可以实时采集对象的语音,并检测其中的情感变化。在对象情感波动时,通过播放音乐和语音进行适当的调节,可以实现良好的对象情绪管理。
[0349]
(二)智能驾驶
[0350]
智能驾驶可以是指车辆行驶过程完全由机器利用人工智能来操作,即无人驾驶,也可以是在有人驾驶的过程中在发生一些紧急状况、司机来不及处理时自动对车辆利用人工智能进行操作。本公开实施例应用于的智能驾驶主要是指后者。在车辆行驶的过程中,可能会发生一些突发路况(例如车辆前方突然闯入行人),司机由于手忙脚乱,容易造成误操作,或者无法及时操作,造成交通事故。而利用智能驾驶可以解决这个问题。当发生紧急事件时,司机或车上的乘客本能地叫喊。车辆终端140实时采集车上的语音,当识别出情感变化后,立即启动摄像头,检测车辆周围环境的变化,从而自动采取一些应对策略(如紧急刹车、并道等),则可以避免一些交通事故的发生。
[0351]
在该场景下,步骤610包括:获取车辆内的第一语音片段和第二语音片段。步骤640包括:基于分类器930的情感变化分类结果,拍摄车辆周围的图像;从拍摄的图像中检测异常事件;根据检测到的异常事件,产生车辆控制指令;步骤650包括:执行该车辆控制指令。
[0352]
由于本实施例用于智能驾驶,步骤610中获取的第一语音片段和第二语音片段可以是车辆中采集的语音段中提取的第一语音片段和第二语音片段。这里的第一语音片段和第二语音片段可以是司机发出的,也可以是车辆中的乘客发出的。
[0353]
图27是根据本公开的实施例的语音情感变化识别方法应用在智能驾驶场景下的模块构架图。除了第一模型910、第二模型920、分类器930之外,该构架还包括摄像头2710、视频分析装置2720、制动装置2730、加/减速装置2740、转向装置2750和显示器2760等。
[0354]
在一个实施例中,分类器930可以在产生的情感变化类别是预定的情感变化类别时,触发摄像头2710拍摄车辆周围图像。在情感变化类别是情感状态的跃迁的情况下,预定
的情感变化类别可以是无情感
→
有情感。这是因为,在出现异常事件时,由于司机或乘客的喊叫等,司机或乘客的情感会从无情感跃迁到有情感。在情感变化类别是具体情感状态的切换的情况下,预定的情感变化类别可以是平静
→
激动等。在出现异常事件时,司机或乘客的情感往往会由平静转为激动。
[0355]
摄像头2710可以安装在车辆的前方,也可以安装在车辆的侧面,等等。可以设置多个摄像头2710,以便从多个角度拍摄车辆周围的图像,以便识别异常事件。摄像头2710可以拍摄静态的图像,例如每1秒拍摄一帧图像,也可以拍摄视频。视频是连续的图像帧,因此,也可以看作是一种图像。
[0356]
摄像头2710拍摄的图像发送到图像分析装置2720进行分析,以从拍摄的图像中检查异常事件。异常事件可以预先定义,包括:车辆前突然闯入行人、两侧的车辆突然并道强行等情况。从拍摄的图像中检查异常事件,可以采用模式识别技术。预先可以定义各种需要识别的模式,如车辆前突然闯入行人等。图像分析装置2720可以由深度神经网络实现,其通过将拍摄的图像与预先输入的待识别模式进行对比,从而检测出图像中的异常事件。
[0357]
车辆控制指令是控制车辆行驶中的各种动作的指令。图像分析装置2720根据不同的异常事件,基于预定的规则,可以产生不同的车辆控制指令。例如,预定规则包括:当异常事件是车辆前方有行人时,产生制动的车辆控制指令;当异常事件是车辆左面出现障碍物时,产生向右转向的车辆控制指令。根据车辆控制指令的不同,图像分析装置2720将不同的车辆控制指令发送到制动装置2730,或加/减速装置2740,或转向装置2750。当车辆控制指令是制动指令时,图像分析装置2720将制动指令发送到制动装置2730,制动装置2730执行该制动指令,将车辆制动。当车辆控制指令是加/减速指令时,图像分析装置2720将加/减速指令发送到加/减速装置2740,加/减速装置2740执行该加/减速指令,增加或减少车辆的行驶速度。当车辆控制指令是转向指令时,图像分析装置2720将转向指令发送到转向装置2750,对车辆行驶的方向进行转向。
[0358]
另外,图像分析装置2720还可以指示显示器2760,对将要的行动进行提示,如图3a所示的“检测到您的情绪由平静变激动,为您启动周围环境检测”、如图3b所示的“检测到前方有行人,为您紧急刹车”等。
[0359]
该实施例中,根据车辆上实时采集的语音识别对象情感变化,从而自动采取一些应对策略,提高了驾驶的安全性。
[0360]
(三)家庭影院的增效
[0361]
本公开实施例也可以用于家庭影院的增效。它可以用于在家庭影院观影中,根据电影中的人物的情感变化,配合以不同的灯光、烟雾、音效等,使对象拥有更加身临其境的体验。
[0362]
在该场景下,步骤610包括:获取正播放的视音频中的第一语音片段和第二语音片段。步骤640包括:基于分类器930的情感变化分类结果,发出增效指令。步骤650包括:在播放该视音频的同时执行该增效指令。
[0363]
图28是根据本公开的实施例的语音情感变化识别方法应用在家庭影院增效场景下的模块构架图。除了第一模型910、第二模型920、分类器930之外,该构架还包括增效策略确定模块2810、灯控制器2820、烟雾控制器2830、音效控制器2840、灯2860、喷雾口2870、扬声器2880和显示器2850等。
[0364]
步骤610中,获取家庭影院终端正播放的视音频的第一语音片段和第二语音片段,可以有多种实现方式。在一种实现方式中,可以在视音频资料未播放之前,直接从视音频资料中获取第一语音片段和第二语音片段。即从音频资料中的语音的波形中直接截取第一语音片段和第二语音片段。在另一种实现方式中,可以在播放视音频的同时启动收音器(未示)采集播放的语音段。然后,从采集的语音段中截取第一语音片段和第二语音片段。
[0365]
步骤640的增效指令即增强观看和收听视音频的体验的指令,例如在观看和收听视音频时辅以灯光效果,或喷雾,或增强音效(例如增加蝉鸣和风声等)的指令。在一个实施例中,可以预先设置情感变化分类结果与增效指令的对应关系表。例如,平静
→
沮丧对应的增效指令可以是灯光变暗的指令;平静
→
高兴对应的增效指令可以是灯光颜色变粉红色的指令、喷出烟雾的指令、和音效增加背景口哨声的指令。这样,当分类器930的情感变化分类结果是特定情感变化分类结果,如平静
→
沮丧、平静
→
高兴等,增效策略确定模块2810基于分类器930的情感变化分类结果,查找该对应关系表,可以发出相应的增效指令。
[0366]
根据增效指令的不同,增效策略确定模块2810将相应增效指令发送到灯控制器2820、烟雾控制器2830和音效控制器2840。如果增效指令是调节灯光的指令,增效策略确定模块2810将调节灯光的指令发送到灯控制器2820,由灯控制器2820执行该指令,调节灯2860的灯光。如果增效指令是调节喷雾的指令,增效策略确定模块2810将调节喷雾的指令发送到烟雾控制器2830,由烟雾控制器2830执行该指令,控制喷雾口2870喷出烟雾。如果增效指令是调节音效的指令,增效策略确定模块2810将调节音效的指令发送到音效控制器2840,由音效控制器2840控制扬声器2880执行该指令,发出相应音效。
[0367]
另外,增效策略确定模块2810还可以指示显示器2850,向对象显示提示,如图4所示的“提示:电影画面由平静转为哀伤,将进入黑灯模式”。
[0368]
该实施例中,实时识别电影中的人物的话语中的情感变化,根据不同情感变化,配合以不同的灯光、烟雾、音效等,达到增强家庭影院的播放效果的作用。
[0369]
(四)家庭防盗报警
[0370]
本公开实施例也可以用于家庭防盗报警。在家庭里发生盗窃、火灾、陌生人闯入等异常状况,家里的人(老人、小孩)本能地会发出尖叫、喊叫等,情感会发生变化。家庭防盗报警终端实时收集语音,检测出语音中的情感变化。当检测到特定的情感变化(如平静
→
激动、平静
→
愤怒等),启动摄像头拍摄视频,远程传给在外的家人的终端,以便在外的家人能够及时了解家中情况,进行处理。
[0371]
在该场景下,步骤610包括:获取家庭中音频中的第一语音片段和第二语音片段。步骤640包括:基于分类器930的情感变化分类结果,拍摄家庭中视频;发出视频传送指令。步骤650包括:根据视频传送指令,将拍摄的视频传送到远程终端。
[0372]
图29是根据本公开的实施例的语音情感变化识别方法应用在家庭防盗报警场景下的模块构架图。它包括家庭防盗报警专用终端140、服务器110和家中在外的人携带的终端140。家庭防盗报警专用终端140和家中在外的人携带的终端140之间通过服务器110进行通信。
[0373]
家庭防盗报警专用终端140除了第一模型910、第二模型920、分类器930之外,还包括摄像头2910、收音器2920、指令产生模块2930、发射器2940等。
[0374]
步骤610中,家庭防盗报警终端140中的收音器2920会实时采集家中对象发出的语
音段,从中获取第一语音片段和第二语音片段。
[0375]
步骤640中,当分类器930的情感变化分类结果是特定情感变化分类结果(如平静
→
激动等),分类器930触发摄像头2910拍摄家中视频,同时触发指令产生模块2930产生视频传送指令。视频传送指令是将视频传送到特定远程终端(家中在外的人的终端)140的指令。发射器2940接收到视频传送指令后,将摄像头2910采集的家中视频通过服务器110发送到远程终端140。
[0376]
远程终端140接收到视频后,会振铃提醒携带远程终端140的人(家中在外的人)。携带远程终端140的人听到振铃后,查看该视频,从而确定家中是否发生了异常状况,在必要时进行处理。
[0377]
该实施例中,在家中发生异常状况时,能够及时将家中的视频远程发送到家中在外的人的终端,从而提醒在外的人查看家中的视频。它能够使得家中在外的人能及时了解家中异常状况,提高安全性。同时,它仅在发生异常状况时发送视频并提醒在外的人查看,相比于实时远程检查的方式,减少了网络资源的占用,也减少了对在外的人的时间的占用。
[0378]
实验效果例
[0379]
图30示出了根据本公开的实施例的语音情感变化识别方法识别语音情感变化的实验结果数据。在该实验中,利用本公开的实施例的语音情感变化识别方法对大量实验样本构成的实验样本集进行处理,得到图30所示的实验结果。事先对实验样本集中的实验样本采用人工方式进行打标签。图30的第一列中的“1”、“2”、“3”为人工打的标签。“1”代表无情感
→
无情感,“2”代表无情感
→
有情感,“3”代表有情感
→
无情感。图30的第一行中的“1”、“2”、“3”代表实际识别出的情感变化分类结果。
[0380]
如图30所示,标签为“1”的样本有1180个,其中1063个在实际语音情感变化识别时也识别为“1”,即识别正确,70个在实际语音情感变化识别时识别为“2”,47个在实际语音情感变化识别时识别为“3”;标签为“2”的样本有74个,其中40个在实际语音情感变化识别时识别为“2”,即识别正确,32个在实际语音情感变化识别时识别为“1”,2个在实际语音情感变化识别时识别为“3”;标签为“3”的样本有79个,其中28个在实际语音情感变化识别时识别为“3”,即识别正确,51个在实际语音情感变化识别时识别为“1”,0个在实际语音情感变化识别时识别为“2”。最终分类的准确率达84.8%。可以看出,根据本公开实施例的语音情感变化识别方法,能够大大提高情感变化的识别准确率。
[0381]
本公开实施例的装置和设备描述
[0382]
可以理解的是,虽然上述各个流程图中的各个步骤按照箭头的表征依次显示,但是这些步骤并不是必然按照箭头表征的顺序依次执行。除非本实施例中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,上述流程图中的至少一部分步骤可以包括多个步骤或者多个阶段,这些步骤或者阶段并不必然是在同一时间执行完成,而是可以在不同的时间执行,这些步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤中的步骤或者阶段的至少一部分轮流或者交替地执行。
[0383]
需要说明的是,在本技术的各个具体实施方式中,当涉及到需要根据目标对象属性信息或属性信息集合等与目标对象特性相关的数据进行相关处理时,都会先获得目标对象的许可或者同意,而且,对这些数据的收集、使用和处理等,都会遵守相关国家和地区的
相关法律法规和标准。此外,当本技术实施例需要获取目标对象属性信息时,会通过弹窗或者跳转到确认页面等方式获得目标对象的单独许可或者单独同意,在明确获得目标对象的单独许可或者单独同意之后,再获取用于使本技术实施例能够正常运行的必要的目标对象相关数据。
[0384]
图31为本公开实施例提供的语音情感变化识别装置3100的结构示意图。该语音情感变化识别装置3100包括:
[0385]
第一获取单元3110,用于获取第一语音片段和第二语音片段,第一语音片段和第二语音片段来自于同一语音段,且第一语音片段在第二语音片段之前;
[0386]
第一生成单元3120,用于将第一语音片段输入第一模型,生成第一向量,并将第二语音片段输入第二模型,生成第二向量,其中,第一模型和第二模型具有同样的结构和参数;
[0387]
分类单元3130,用于将第一向量和第二向量输入分类器,由分类器对第一语音片段到第二语音片段的情感变化进行分类。
[0388]
可选地,第一语音片段到第二语音片段的情感变化包括情感状态之间的跃迁,情感状态包括有情感和无情感;
[0389]
语音情感变化识别装置还包括:第一训练单元(未示),用于通过以下过程联合训练第一模型、第二模型和分类器:
[0390]
构建第一样本集,第一样本集中的第一样本包括第一样本语音片段和第二样本语音片段,第一样本具有第一样本标签,用于指示第一样本语音片段到第二样本语音片段情感状态之间的跃迁;
[0391]
将第一样本语音片段输入第一模型,生成第一样本向量,并将第二样本语音片段输入第二模型,生成第二样本向量;
[0392]
将第一样本向量和第二样本向量输入分类器;
[0393]
基于分类器的分类结果与第一样本标签的比较,构造第一误差函数,并基于第一误差函数调整第一模型、第二模型和分类器的参数。
[0394]
可选地,语音情感变化识别装置3100还包括:
[0395]
第二获取单元(未示),用于如果分类出的情感变化为跃迁到有情感,获取第二语音片段的词向量序列;
[0396]
第一输入单元(未示),用于将词向量序列输入语义编码模型,得到第二语音片段的语义向量;
[0397]
第二输入单元(未示),用于将词向量序列和语义向量输入情感分类模型,得到第二语音片段的情感类别。
[0398]
可选地,第一语音片段到第二语音片段的情感变化包括第一语音片段的情感类别和第二语音片段的情感类别;
[0399]
语音情感变化识别装置还包括:第二训练单元(未示),用于通过以下过程联合训练第一模型、第二模型和分类器:
[0400]
构建第二样本集,第二样本集中的第二样本包括第三样本语音片段和第四样本语音片段,第二样本具有第二样本标签,用于指示第三样本语音片段的情感类别和第四样本语音片段的情感类别;
[0401]
将第三样本语音片段输入第一模型,生成第三样本向量,并将第四样本语音片段输入第二模型,生成第四样本向量;
[0402]
将第三样本向量和第四样本向量输入分类器;
[0403]
基于分类器的分类结果与第二样本标签的比较,构造第二误差函数,并基于第二误差函数调整第一模型、第二模型和分类器的参数。
[0404]
可选地,语音情感变化识别装置3100还包括:
[0405]
第三输入单元(未示),用于将第一向量和第二向量输入说话者判决器,由说话者判决器判定第一语音片段的发出者和第二语音片段的发出者是否相同;
[0406]
第三训练单元(未示),用于通过以下过程联合训练第一模型、第二模型、分类器和说话者判决器:
[0407]
构建第三样本集,第三样本集中的第三样本包括第五样本语音片段和第六样本语音片段,第三样本具有第三样本标签和第四样本标签,第三样本标签用于指示第五样本语音片段到第六样本语音片段的情感变化,第四样本标签用于指示第五样本语音片段的发出者和第六样本语音片段的发出者是否相同;
[0408]
将第五样本语音片段输入第一模型,生成第五样本向量,并将第六样本语音片段输入第二模型,生成第六样本向量;
[0409]
将第五样本向量和第六样本向量输入分类器,并将第五样本向量和第六样本向量输入说话者判决器;
[0410]
基于分类器的分类结果与第三样本标签的比较、说话者判决器的判定结果与第四样本标签的比较,构造第三误差函数,并基于第三误差函数调整第一模型、第二模型、分类器和说话者判决器的参数。
[0411]
可选地,第三训练单元具体用于:
[0412]
基于分类器的分类结果与第三样本标签的比较,构造第一误差子函数;
[0413]
基于说话者判决器的判定结果与第四样本标签的比较,构造第二误差子函数;
[0414]
基于第一误差子函数与第二误差子函数,构造第三误差函数。
[0415]
可选地,第三训练单元具体用于:
[0416]
针对第三样本集中的第三样本,构造第一键,其中,第一键为第一值时指示分类器的分类结果与第三样本标签相同,第一键为第二值时指示分类器的分类结果与第三样本标签不同;
[0417]
获取分类器对分类结果的第一预测概率;
[0418]
基于第一键和第一预测概率,构造第一误差子函数。
[0419]
可选地,第三训练单元具体用于:
[0420]
针对第三样本集中的第三样本,构造第二键,其中,第二键为第一值时指示说话者判决器的判定结果与第四样本标签相同,第二键为第二值时指示说话者判决器的判定结果与第四样本标签不同;
[0421]
获取说话者判决器对判定结果的第二预测概率;
[0422]
基于第二键和第二预测概率,构造第二误差子函数。
[0423]
可选地,第一获取单元3110具体用于:
[0424]
对第一语音片段和第二语音片段所在的语音段进行语音识别,得到文本段;
[0425]
在文本段中选取第一子文本段和第二子文本段,第一子文本段在第二子文本段之前;
[0426]
根据第一子文本段中语句的注意力分数,在第一子文本段中选取第一语句,根据第二子文本段中语句的注意力分数,在第二子文本段中选取第二语句;
[0427]
从语音段中获取第一语句对应的语音片段作为第一语音片段,获取第二语句对应的语音片段作为第二语音片段。
[0428]
可选地,语音情感变化识别装置3100还包括:
[0429]
提取单元(未示),用于从第一语音片段中提取第一情感特征序列,从第二语音片段中提取第二情感特征序列;
[0430]
合并单元(未示),用于将第一情感特征序列并入第一向量,将第二情感特征序列并入第二向量。
[0431]
可选地,语音情感变化识别装置3100还包括:
[0432]
第三获取单元(未示),用于获取第三语音片段,第三语音片段与第二语音片段来自于同一语音段,且在第二语音片段之后;
[0433]
第二生成单元(未示),用于将第三语音片段输入第三模型,生成第三向量,其中,第三模型与第二模型具有同样的结构和参数;
[0434]
分类单元3130具体用于:将第一向量、第二向量和第三向量输入分类器,由分类器对第一语音片段到第二语音片段的情感变化进行分类,并对第二语音片段到第三语音片段的情感变化进行分类。
[0435]
可选地,语音情感变化识别装置3100还包括:
[0436]
确定单元(未示),用于根据分类器的情感变化分类结果,确定对情感变化分类结果的响应;
[0437]
执行单元(未示),用于执行响应。
[0438]
参照图32,图32为实现本公开实施例的语音情感变化识别方法的终端140的部分的结构框图,该终端包括:射频(radio frequency,简称rf)电路3210、存储器3215、输入单元3230、显示单元3240、传感器3250、音频电路3260、无线保真(wireless fidelity,简称wifi)模块3270、处理器3280、以及电源3290等部件。本领域技术人员可以理解,图32中示出的终端140结构并不构成对手机或电脑的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
[0439]
rf电路3210可用于收发信息或通话过程中,信号的接收和发送,特别地,将基站的下行信息接收后,给处理器3280处理;另外,将设计上行的数据发送给基站。
[0440]
存储器3215可用于存储软件程序以及模块,处理器3280通过运行存储在存储器3215的软件程序以及模块,从而执行终端的各种功能应用以及数据处理。
[0441]
输入单元3230可用于接收输入的数字或字符信息,以及产生与终端的设置以及功能控制有关的键信号输入。具体地,输入单元3230可包括触控面板3231以及其他输入装置3232。
[0442]
显示单元3240可用于显示输入的信息或提供的信息以及终端的各种菜单。显示单元3240可包括显示面板3241。
[0443]
音频电路3260、扬声器3261,传声器3262可提供音频接口。
[0444]
在本实施例中,该终端140所包括的处理器3280可以执行前面实施例的语音情感变化识别方法。
[0445]
本公开实施例的终端140包括但不限于手机、电脑、智能语音交互设备、智能家电、车载终端、飞行器等。本发明实施例可应用于各种场景,包括但不限于云技术、人工智能、智慧交通、辅助驾驶等。
[0446]
图33为实施本公开实施例的语音情感变化识别方法的服务器110的部分的结构框图。服务器110可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上中央处理器(central processing units,简称cpu)3322(例如,一个或一个以上处理器)和存储器3332,一个或一个以上存储应用程序3342或数据3344的存储介质3330(例如一个或一个以上海量存储装置)。其中,存储器3332和存储介质3330可以是短暂存储或持久存储。存储在存储介质3330的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对服务器3300中的一系列指令操作。更进一步地,中央处理器3322可以设置为与存储介质3330通信,在服务器3300上执行存储介质3330中的一系列指令操作。
[0447]
服务器3300还可以包括一个或一个以上电源3326,一个或一个以上有线或无线网络接口3350,一个或一个以上输入输出接口3358,和/或,一个或一个以上操作系统3341,例如windows servertm,mac os xtm,unixtm,linuxtm,freebsdtm等等。
[0448]
服务器3300中的处理器可以用于执行本公开实施例的语音情感变化识别方法。
[0449]
本公开实施例还提供一种计算机可读存储介质,计算机可读存储介质用于存储程序代码,程序代码用于执行前述各个实施例的语音情感变化识别方法。
[0450]
本公开实施例还提供了一种计算机程序产品,该计算机程序产品包括计算机程序。计算机设备的处理器读取该计算机程序并执行,使得该计算机设备执行实现上述的语音情感变化识别方法。
[0451]
本公开的说明书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本公开的实施例例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“包含”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或装置不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或装置固有的其它步骤或单元。
[0452]
应当理解,在本公开中,“至少一个(项)”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,用于描述关联对象的关联关系,表示可以存在三种关系,例如,“a和/或b”可以表示:只存在a,只存在b以及同时存在a和b三种情况,其中a,b可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。“以下至少一项(个)”或其类似表达,是指这些项中的任意组合,包括单项(个)或复数项(个)的任意组合。例如,a,b或c中的至少一项(个),可以表示:a,b,c,“a和b”,“a和c”,“b和c”,或“a和b和c”,其中a,b,c可以是单个,也可以是多个。
[0453]
应了解,在本公开实施例的描述中,多个(或多项)的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。
[0454]
在本公开所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以
通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
[0455]
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0456]
另外,在本公开各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0457]
集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本公开的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机装置(可以是个人计算机,服务器,或者网络装置等)执行本公开各个实施例方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-only memory,简称rom)、随机存取存储器(random access memory,简称ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0458]
还应了解,本公开实施例提供的各种实施方式可以任意进行组合,以实现不同的技术效果。
[0459]
以上是对本公开的实施方式的具体说明,但本公开并不局限于上述实施方式,熟悉本领域的技术人员在不违背本公开精神的条件下还可作出种种等同的变形或替换,这些等同的变形或替换均包括在本公开权利要求所限定的范围内。
当前第1页1
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!